

Every audio deepfake detection vendor publishes an accuracy number clustered around 99%, and almost none of those numbers mean the same thing because:
- each one is computed on a test set the vendor controls
- the threshold is up to the vendor running the bench
- it’s measured against attack distributions that may or may not reflect what attackers actually deploy today
- the test data is often known to the vendor, who can then train specifically on the samples being measured
This is the problem Podonos set out to fix. In May 2026, they ran a neutral audio deepfake detection benchmark across eight deepfake detection systems — four commercial APIs and four open-source models — using a private-label test set built around modern voice-cloning tools, realistic audio formats, and production deployment conditions. The labels stayed private so no vendor could tune against them.
We ranked first. Here's what the data actually shows, and why the numbers that matter most aren't the ones at the top of the leaderboard.
The Three Requirements Production Actually Imposes
Production-grade audio deepfake detection has three hard requirements, and most benchmarks only test one of them properly.
- Accuracy at 95th percentile across thousands of API hits.
- Real-time inference — anything over RTF 1.0 can't keep up with a live stream.
- Sub-second latency that holds under real load, not just one test call.
That third requirement is where most benchmarks fail buyers: they report best-case performance, not performance under real load. Podonos tested at the threshold vendors actually ship with, not the threshold that optimizes their score. They also tested across six file formats: mp3, wav, flac, ogg, m4a, webm because production audio doesn't arrive as clean 16kHz wav files.
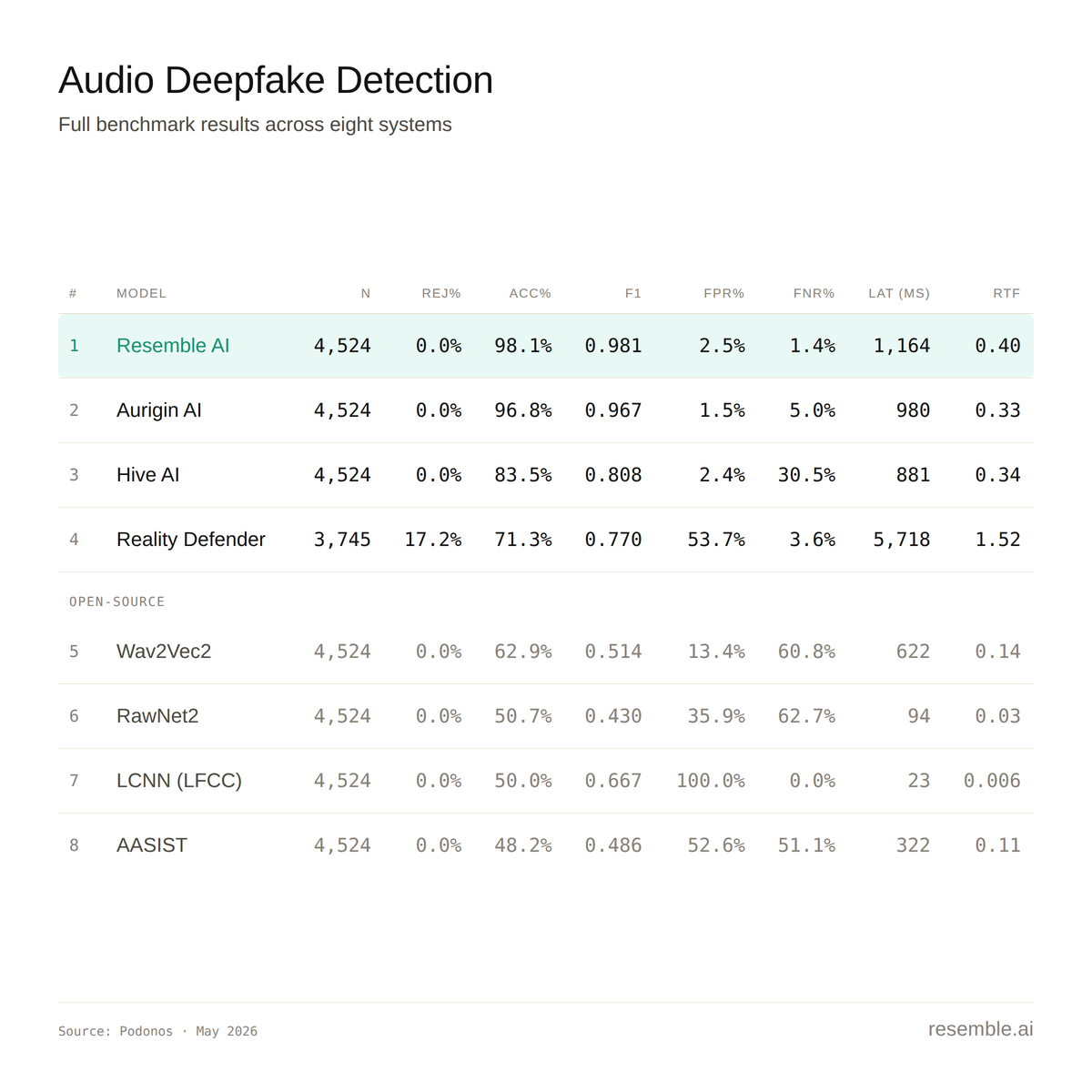
What the Leaderboard Shows
.png)
The gap between the top two systems and the rest of the field is stark. Resemble AI ranked first at 98.1% accuracy with an F1 of 0.981. Aurigin AI ranked second at 96.8%. The distance from second place to third — Hive at 83.5% is more than 13 percentage points. From there, it drops fast: Reality Defender at 71.3%, and the four open-source models (Wav2Vec2, RawNet2, LCNN, AASIST) between 48% and 63%.
All four open-source models were trained on ASVspoof 2019 LA, a dataset that predates ElevenLabs, F5-TTS, Chatterbox, and essentially everything attackers are using today. On this benchmark which included approximately 25 modern TTS systems in its synthetic audio they performed at or below unaided human performance. The benchmark authors were direct about why: the failure is not about open-source versus commercial. It is about the obsolescence of ASVspoof as a training distribution. A detector trained on 2019 attacks does not generalize to 2026 attacks.
Security teams evaluating detection tools should ask their vendors directly: what attack distribution was your model trained on, and when was it last updated?
The Number That Actually Determines Your Risk: False Negative Rate
Overall accuracy tells you whether a system can do the job, but not what kind of mistakes it makes when it fails and in a fraud program, those mistakes have very different costs.
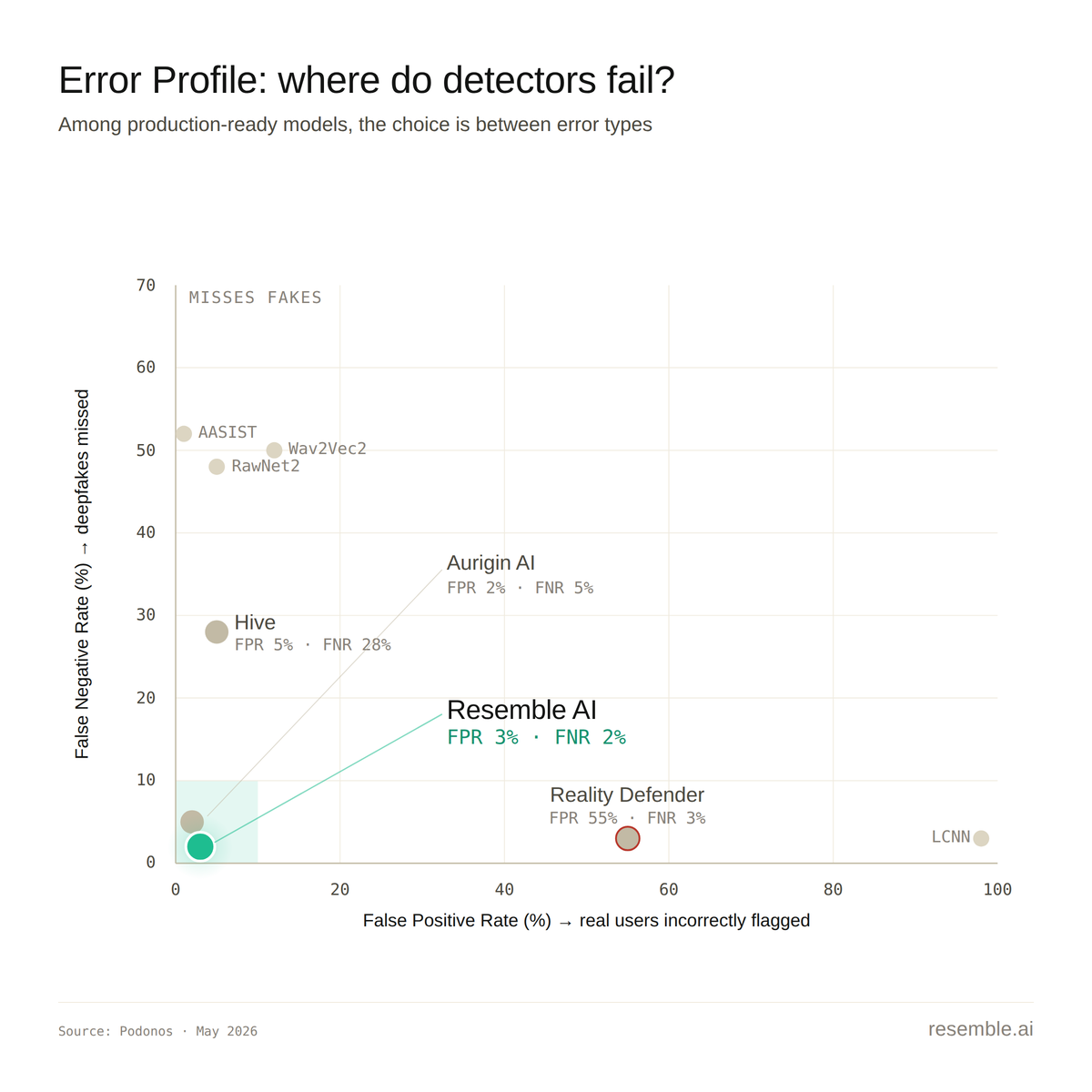
Resemble AI's profile: 2.5% false positive rate, 1.4% false negative rate. That means we flag 2.5% of legitimate audio as suspicious, and we miss 1.4% of actual deepfakes.
Aurigin AI's profile: 1.5% false positive rate, 5.0% false negative rate. They flag legitimate audio less often, but miss roughly 3.5x as many fakes.
At F1 0.96+ and real-time latency, both are deployable in production. Where they differ is in where they fail and that distinction matters more than the headline accuracy gap between them.
The right question for your team is which error is more expensive in your specific deployment:
- Voice-fraud screening, KYC, content provenance: a missed deepfake is a fraud event. Optimise for the lowest false negative rate you can get at a threshold your operations team can actually work with.
- Content moderation at scale, automated takedowns, journalism verification: incorrectly flagging legitimate audio generates its own operational and reputational cost. Optimise for false positive rate instead.
We hear this framing in almost every evaluation conversation, and most teams land somewhere between these poles which is why the ability to tune thresholds against your own traffic matters as much as where the defaults sit.
Reality Defender's Result Deepdive
Reality Defender's numbers are worth looking at in detail: 71.3% accuracy, 53.7% false positive rate, 17.2% rejection rate, real-time factor of 1.52.
To translate: more than half of real audio was flagged as fake. Nearly one in five clips under 1.5 seconds was not evaluated at all. And the system runs slower than real-time, meaning it cannot keep up with a live voice stream.
A 53.7% false positive rate in a production KYC or call-center authentication context would generate an enormous volume of incorrect flags — the operational overhead would be significant.
The latency point matters independently of accuracy. Streaming and real-time use cases require RTF below 1.0. A system at RTF 1.52 fails this bar regardless of any other metric. Resemble AI and Aurigin AI both land at RTF 0.33–0.40, well within real-time budgets.
.png)
What the Benchmark Doesn't Cover (and Why That Matters)
The Podonos team was explicit about caveats, and buyers evaluating detection tools should carry them into any vendor conversation.
The benchmark covers English only, which is a real gap as non-English voice cloning is a growing attack surface and most detection tooling hasn't caught up with it. Our own research team has been working on this directly: MLAAD v10, published by Resemble AI researchers alongside collaborators, covers 1,000+ hours of audio across 175 generative models and 54 languages, making it the most comprehensive multilingual audio deepfake detection dataset built to date. If your operations run across multiple languages, the MLAAD paper is a useful asset to read before you evaluate any detection vendor on non-English audio.
Any benchmark is a snapshot, and the TTS landscape moves fast enough that detection coverage degrades against attack vectors that weren't in the training data when the test was run. A detection vendor whose models were last updated six months ago is not protecting you from today's threats. Our research team updates detection models on a weekly to bi-weekly cadence, tracking new generative AI releases as they emerge.
The benchmark also tested at vendors' shipped thresholds, which is the right call for production comparison. But it means error profiles are a function of where each vendor chose to set their default and that threshold can often be tuned. If your deployment needs a different FPR/FNR balance than the default, ask whether the vendor supports threshold customization.
The Questions to Take Into Your Evaluation
If you're evaluating audio deepfake detection right now, these are the questions that matter more than the leaderboard:
- What is the FPR/FNR tradeoff at your shipped decision threshold — and can that threshold be adjusted for our use case?
- What is p95 latency under our projected QPS, not best-case demo performance?
- How does RTF hold across our audio length distribution, including the long tail?
- What deployment model do you support — cloud only, on-premises, air-gapped — and does that fit our data residency requirements?
The Podonos benchmark gives you a neutral baseline for accuracy and real-time performance. The questions above fill the gaps it deliberately doesn't cover.
We think an independent test that holds labels private and tests against modern attack distributions is exactly the right way to evaluate detection tools. We're happy to have ranked first on it and we're equally happy to help you test against your own data before you make a decision.
Book a demo to see Resemble Detect running on your audio today.
.avif)

