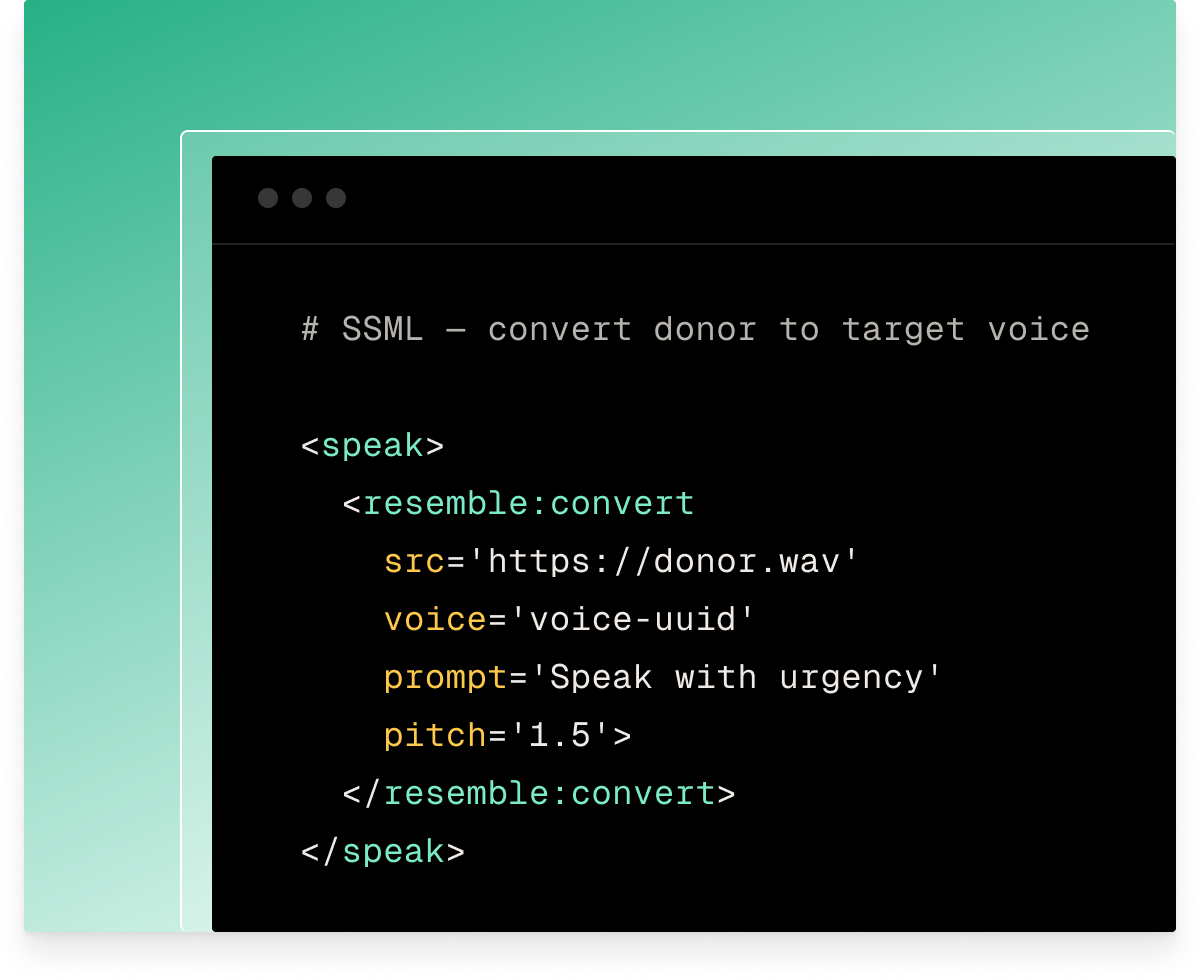
Speech-to-speech (STS) lets you demonstrate the delivery instead of leaving it to the model. Record the line, pass a target voice UUID, and the engine converts your voice while keeping your performance unchanged.
TTS generates speech from text, the AI decides the delivery. STS takes a recorded human performance and converts the voice, preserving how it was delivered.
Do I need to be a voice actor to use STS?
No. Record yourself delivering the line clearly. Quality depends on a clean single-speaker WAV, not professional voice acting.
Can I convert one recording to multiple voices?
Yes. Submit the same donor WAV with different target voice UUIDs. Each conversion preserves the original performance in a different voice.
How do I steer the output without re-recording?
Use the prompt attribute on the <resemble:convert> tag. Specify accent, tone, or speaking style (e.g. 'Speak in a British accent', 'Speak with excitement'). No additional recording required.
What voice does the target need to be?
Any Resemble voice: cloned or from the voice library. The target voice must have 10+ minutes of training dataset.
How quickly can we integrate?
No. If you're already integrated with Resemble TTS, STS requires only a change to the SSML input.
Get complete generative AI security
Join thousands of developers and enterprises securing with Resemble AI