

Voice AI has reached the point where listener-level detection of synthetic speech is unreliable for most languages. We can no longer definitively say "this sounds synthetic" vs "this sounds real" by ear alone, and our own evaluation work for this release is part of how we know it.
Today, June 10, 2026, we are releasing Chatterbox Multilingual v3 following the launch of an NVIDIA NIM - now available in the NVIDIA build catalog.
Chatterbox Multilingual v3 is the next general-purpose multilingual TTS model in the Chatterbox family. It supports 25 total languages (including 4 dialects and 6 tuned Language Pack models), keeps the same 0.5B Llama backbone as v2 under MIT license, and ships meaningful improvements in speaker similarity, hallucination rate, and conversational naturalness.
Chatterbox Multilingual v3 open source ships with PerTh watermarking embedded by default on every self-hosted audio output, across every supported language. Provenance and the ability to automatically watermark outputs is a major component of this release as regulation like the EU AI Act Article 50 loom, and as voice AI and text-to-speech models strive to be more trustworthy and verifiable at generation time.
This post covers the watermarking architecture first, then walks through the v3 model improvements, the language-by-language evaluation, the NVIDIA NIM deployment path, and the limitations we know about.
Why Watermark Voice AI Outputs
Every audio file generated by v3 and the Single-Language Pack is PerTh watermark ready. PerTh is a neural watermarking system that encodes an imperceptible signal into the audio waveform at generation time. It is designed to survive the manipulations that strip metadata-based provenance: MP3 and Opus compression, telephony codecs, audio editing, format conversion, partial clipping, and the resampling that happens when audio moves between platforms. The watermark is detectable with near 100% accuracy on unmodified outputs and degrades gracefully under manipulation.
We made the decision early in Chatterbox's development to ship watermarking by default in the open source repo, and that decision matters more for v3 than it did for earlier releases. v2 was good enough that synthetic outputs were already difficult to distinguish from real recordings without forensic tool results.
The v1 Hugging Face TTS Arena results were the first signal that we were past the listener-level distinguishability threshold on English). v3 is meaningfully better than v2. The ability to confidently state "this sounds synthetic" vs "this sounds real" is now low enough on most supported languages that listener-level detection is unreliable, which puts more pressure on technical provenance signals like watermarking.
On-by-default watermarking, applied at the final stage of text-to-speech generation, is what produces a useful provenance signal at the scale audio AI now operates at. The argument is not that detection will fail, it is that provenance and detection together cover more of the threat surface than either alone, and the marginal cost of embedding a watermark at generation time is small enough that we see no reason to leave it off.
The PerTh detection library is on GitHub under permissive license, so any developer integrating Chatterbox can verify provenance downstream without paying for or licensing additional tooling. To add watermarking to Chatterbox Multilingual outputs deployed via NVIDIA NIM, contact us for a Watermarker API key.
Watermarking + coming regulation
Regulators have started to converge on the answer that the field has been converging on for a few years. The EU AI Act Article 50 requires that AI-generated audio be marked in a machine-readable format starting in August 2026. The TAKE IT DOWN Act signed into law in the US last year creates new content-traceability requirements for synthetic media. PerTh was designed before either of those frameworks existed, but the design choices that made it useful in 2023 (imperceptibility, robustness to manipulation, frame-level encoding) are the same ones that make it compliant with the emerging regulatory environment.
What's new in v3
Chatterbox Multilingual v3 uses the same 0.5B Llama-based backbone as v2. The improvements come primarily from data, training, and language-specific specialization rather than from any increase in model size.
For v3, we expanded and rebalanced the multilingual training mixture with a stronger focus on high-quality, expressive, conversational data. The data recipe places more emphasis on priority languages and regional variants where users need stronger pronunciation control and more stable speaker transfer. We expanded the multilingual training mixture from 25.6k hours to 36.7k hours, and improved balancing across script reading, narration, and conversational data to better match real-world usage patterns we observed in the v2 deployment.
The training updates were aimed at the main reliability issues we observed in earlier multilingual checkpoints. We targeted off-prompt continuation, repetition, accent drift, and degraded speaker similarity in cross-language voice cloning specifically. v3 uses a cleaner and more controlled fine-tuning regime with fine-grained data labeling, stricter sample filtering, and language-specific refinement for the Single-Language Pack. The Single-Language Pack is designed to complement the general multilingual model by giving selected languages and dialects dedicated capacity and tighter quality control.
The result is a model that is more stable, more expressive, and more conversational while keeping the same 0.5B footprint. In our internal testing, v3 shows improved speaker similarity across languages, fewer hallucination-style failures, and more natural delivery for both long-form narration and short voice-agent prompts. v3 is a stronger general-purpose multilingual model for developers building voice agents, creator tools, audiobook workflows, and multilingual speech applications. For priority languages where regional pronunciation or specialized behavior matters most, the Single-Language Pack provides dedicated checkpoints.
Languages supported in v3
- Arabic (ar)
- Chinese (zh) - Language Pack
- Czech (cs)
- Dutch (nl)
- English (en)
- Finnish (fi)
- French (fr)
- German (de)
- Hebrew (he)
- Hindi (hi) - Language Pack
- Italian (it)
- Japanese (ja)
- Korean (ko)
- Norwegian (no)
- Polish (pl)
- Portuguese (pt)
- Portuguese Brazilian (pt-br) Language Pack - Dialect
- Portuguese Portugal (pt-pt) Language Pack - Dialect
- Russian (ru)
- Spanish (es)
- Spanish Mexico / LATAM (es-mx) Language Pack - Dialect
- Spanish Spain (es-es) Language Pack - Dialect
- Swedish (sv)
- Turkish (tr)
- Vietnamese (vi)
How we evaluated v3
We measured v3 across all supported languages using a transcription-based Character Error Rate (CER) protocol. For each language, we generated 100 samples from held-out prompts, transcribed the synthesized audio with `whisper-large-v3` set to the target language, and computed CER against the source text. The intuition is straightforward: if a TTS model hallucinates content, drifts into another language, or repeats itself, an ASR system attempting to transcribe its output back to text will introduce character-level errors that compound visibly. Lower CER on this protocol means the model is saying what it was asked to say.
We chose CER rather than the more common Word Error Rate because it is more sensitive to the failure modes we most wanted to address from v2: small mispronunciations, partial repetitions, and character-level drift in languages where word boundaries are ambiguous, like Chinese and Japanese. WER tends to mask these failures because a single garbled syllable inside an otherwise correct word can register as a full word error or no error depending on tokenization.
CER is still an imperfect proxy for what we actually care about. It captures intelligibility and stability, but it does not measure prosody, speaker similarity, or expressive delivery, all of which matter for the conversational and voice-agent use cases v3 is built for. The results in this post should be read as evidence of v3's intelligibility and stability, not as a complete picture of quality. We are working on an extended evaluation suite that adds subjective Mean Opinion Score (MOS) ratings and objective speaker similarity benchmarks, and we will publish those numbers when they are ready.
Benchmark Results
CER by Language
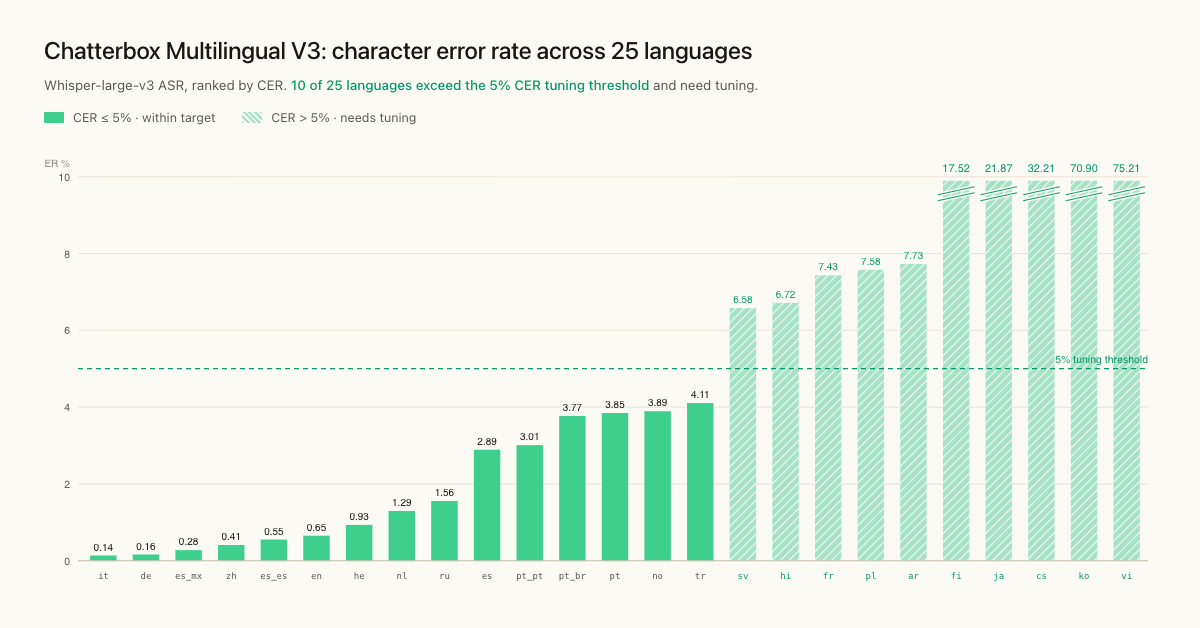
The strongest pattern in the data is at the top. Italian and German base v3 land under 0.20% CER, and the Single-Language Pack variants for Latin American Spanish (0.28%), Mandarin Chinese (0.41%), and European Spanish (0.55%) sit alongside them in the sub-1% band. English (0.65%) and Hebrew (0.93%) round out the languages where v3 reaches the measurement floor of our transcription-based protocol. For all of these, the next round of improvements will need to come from prosody and speaker-similarity work rather than from reducing transcription errors.
The middle band is roughly 1% to 5% CER and covers Dutch, Russian, base Spanish, European Portuguese, Brazilian Portuguese, base Portuguese, Norwegian, and Turkish. These are languages where v3 is production-ready for general use, with the dialect-specific Single-Language Pack models pulling Spanish from 2.89% base to 0.28-0.55% in the dialect variants. Portuguese shows a more modest improvement from the base model (3.85%) to the dialect packs (3.01-3.77%), which is consistent with the underlying point about specialization: the headroom for the dedicated models is largest where the base model has the most distance left to travel.
Hindi, French, Polish, and Arabic land in the 6-8% range, which is meaningfully worse than the front-runners but still usable in production with appropriate testing. Hindi is in the Single-Language Pack at 2.55 - 6.72% CER, which is roughly where the base Hindi performance was in earlier checkpoints. The dedicated capacity is doing the work of preventing degradation rather than driving large gains, and we are continuing to invest in Hindi-specific data work for future releases.
The bottom of the table tells a different story, and we discuss the languages that did not reach production quality in the limitations section below.
Results — Latency and deployment
On a single H100 with our unoptimized PyTorch implementation, v3 measures the following on our internal benchmark:
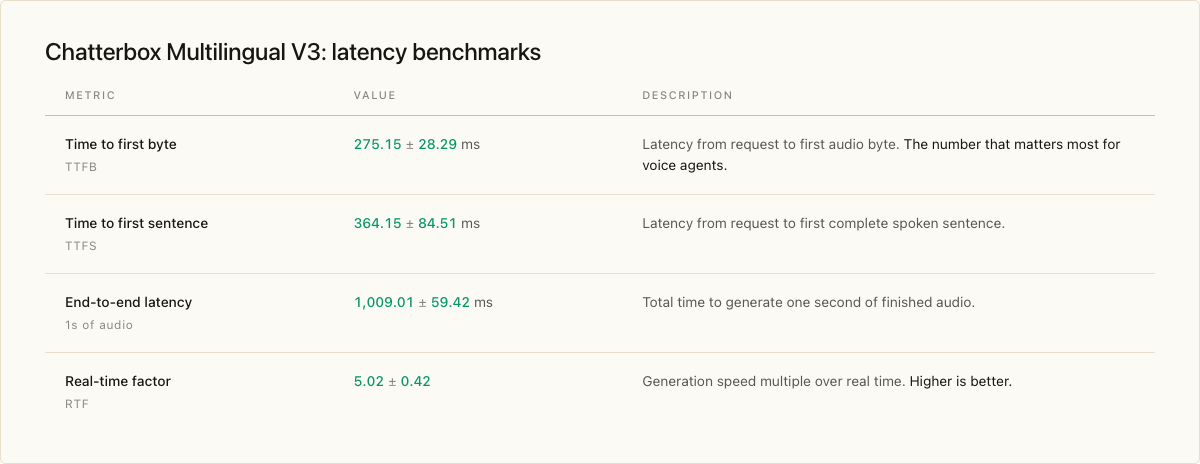
For voice-agent and conversational deployments, TTFB is the number that matters: it determines how quickly the first audible response reaches the user. Under 300ms is at the threshold of what feels like natural conversational pacing, which v3 clears with headroom. The RTF of approximately 5 means v3 generates audio roughly five times faster than real time on a single H100, leaving room for batching multiple concurrent streams on the same GPU.
These are the unoptimized PyTorch numbers. The NVIDIA NIM release covered in the next section ships with TensorRT-LLM acceleration, optimized batching, and dynamic shape support, which lower TTFB and raise concurrent throughput substantially relative to this baseline. This means quicker round trip latencies when deployed as part of a voice AI agent, or faster responses in a one way use case where the voice output is the end goal.
For Enterprise-Scale Deployment: NVIDIA NIM Available
NVIDIA NIM, is an optimized, containerized inference endpoint with TensorRT-LLM acceleration,of the model. In the table below, you can see NVIDIA NIM delivers 2x-39x throughput vs unoptimized PyTorch while supporting enterprise-scale concurrent inference.
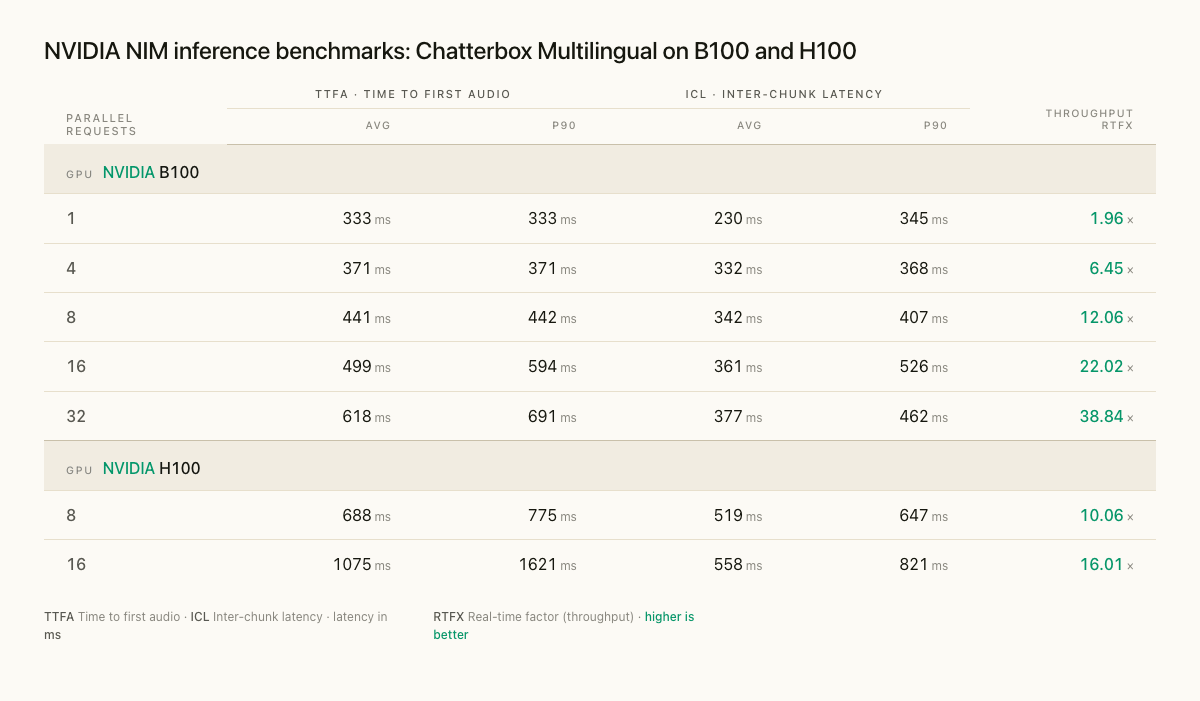
NVIDIA NIM provides optimized batching, autoscaling, and the deployment plumbing that enterprise voice-agent infrastructure typically needs.
For Chatterbox v3 specifically, that means meaningfully lower latency than the unoptimized PyTorch numbers in the table above, dynamic batching for concurrent streams, and a deployment path that fits cleanly into existing NVIDIA enterprise stacks.
The way we think about the choice between the two: use the open-weight model when you want full control over the deployment, are running at moderate volume, or are doing research, fine-tuning, or evaluation work. Use NVIDIA NIM for production when you want:
- Full control over the deployment
- Security patches on the NIM container
- Free API for evaluation available with build.nvidia here
All at the scale where the optimization and operational plumbing pay for themselves. Both options ship from the same v3 weights and produce equivalent output quality. The difference is in the inference layer and how much of the production engineering you want to own.
Why ship a general model and a Single-Language Pack at the same time
The architectural decision behind this release was not technical, it was about how developers actually deploy multilingual TTS. We started with the assumption that one good general model should be enough, but the v2 deployment data disputed that assumption in two specific ways.
First, the highest-volume single-language users of v2 were not deploying it in English. They were deploying it in Hindi, Brazilian Portuguese, and Latin American Spanish, and they were running into quality ceilings that the general multilingual model could not break through no matter how much fine-tuning they did at the application layer. These were languages where v2 had measurable headroom against what a dedicated model could achieve, and where the deployment economics justified a larger, language-specific model.
Second, the dialect question turned out to matter more than we initially expected. European Portuguese and Brazilian Portuguese share most of their grammar and a large fraction of their vocabulary, but they have substantially different phonologies, and Portuguese-speaking listeners can distinguish them effortlessly. A model trained on broadly-balanced Portuguese data produces speech that sounds technically correct but slightly off to native ears of either variant. The same applies, less dramatically, to European Spanish and Latin American Spanish. The Single-Language Pack lets us serve each variant from a model that has only ever seen that variant, which is the closest we can get to native-sounding output without language-specific architectural changes.
The tradeoff is parameter efficiency. Six dedicated models cost more to host than one general model, and they only make sense when the deployment volume justifies the additional infrastructure. We expect most developers will use v3 base for breadth and reach for a Single-Language Pack model only when the language matters enough commercially to be worth a dedicated GPU footprint.
Model Cards on Hugging Face
What v3 still does not do well
v3 has known weaknesses we want to surface in detail rather than leave them to be discovered by developers in production.
Korean and Vietnamese are not at production quality.
v3 generates Korean and Vietnamese speech with CERs of 70.90% and 75.21% respectively, both more than an order of magnitude worse than the next-weakest language in the supported set. The root cause is training data: we do not have sufficient volume of high-quality paired text-audio data in either language across the speaker distribution the model needs to generalize properly. v3 will produce Korean and Vietnamese output, but we recommend against using v3 for commercial deployments in either language until we have shipped an improvement. We are actively working on the data side and expect to release either upgraded multilingual checkpoints or dedicated Single-Language Pack models as follow-ups.
Czech, Japanese, and Finnish are usable with caveats.
Czech at 32.21% CER, Japanese at 21.87%, and Finnish at 17.52% are all behind the front-runners but still in the range where the output is intelligible for many applications. We attribute the gap to a combination of factors: smaller training data volume than the well-supported European languages, tokenization challenges (particularly for Japanese mixed scripts of hiragana, katakana, and kanji), and prosodic features our current evaluation does not capture well. Developers building applications in any of these three languages should evaluate carefully on their specific content before deploying.
Watermarking has limits we are continuing to characterize.
PerTh is robust against the manipulations we have tested, but we have not yet published systematic robustness curves under adversarial conditions (specifically: targeted attacks designed to strip the watermark without destroying audio quality). The watermark also produces a binary signal for "this audio was generated by Chatterbox," not a model-version signal or a tenant-attribution signal. These capabilities and on their way, and we are working with the C2PA community on the interop standards that would let multiple TTS providers' watermarks be verified through a single library.
The deeper limitation is that CER does not capture everything.
A model can score well on transcription-based metrics while still missing prosody, sounding unnatural, or failing on speaker similarity in voice-cloning use cases. The numbers in this post are evidence of intelligibility and stability, not a complete picture of quality. We are working on the next round of evaluations and expect those numbers to surface tradeoffs the current results hide.
What's next
The work continues in four directions. The first is closing the gap on the languages where v3 is weak, particularly Korean and Vietnamese, which will require both data work and likely architectural attention for languages with complex tokenization. The second is extending the evaluation protocol to add subjective quality and speaker similarity metrics that the current CER-based approach misses. The third is broadening the Single-Language Pack to additional languages where the deployment volume and quality headroom justify dedicated models. The fourth is the watermarking work: tenant attribution, model-version signaling, and adversarial robustness characterization.
.avif)