PerTh is our neural speech watermarker — a deep network that embeds imperceptible, tamper-resistant data into every clip Resemble creates, so you can verify its origin long after it leaves your app.
Photo-editing tools taught us we can’t trust images on sight. Generative AI now does the same for speech with almost none of the skill barrier. PerTh is our answer: every clip Resemble generates leaves with an invisible signature you can verify later.
Encode at generation
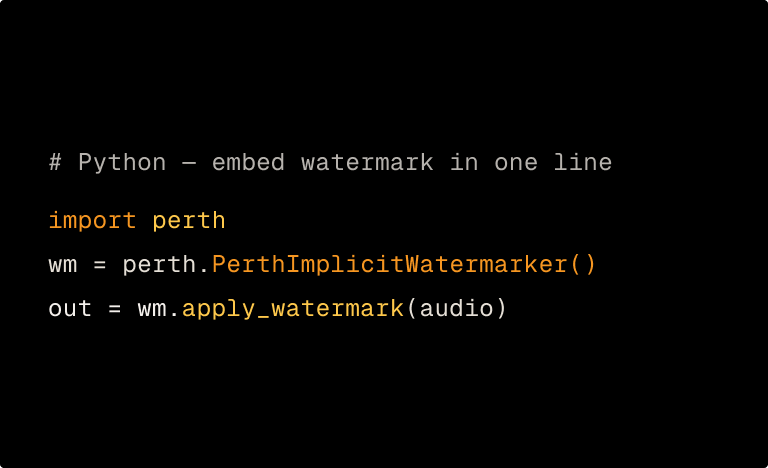
Every Resemble-generated clip passes through the PerTh model, which embeds a data payload into frequency regions chosen using psychoacoustics inaudible to human ears by design.
Withstand real-world handling
The payload rides along through resampling, MP3 compression, time-stretching, time-shifting, and added noise. Audio gets edited in production — PerTh keeps up.
Verify on demand
Run suspect audio through our decoder. If it came from Resemble, we recover the embedded data even from a short segment of non-silent speech.
A watermark is only useful if it survives the journey from generation to wherever your audio ends up. PerTh is designed for the messy reality of the modern content pipeline.
The model exploits the way humans perceive audio, then encodes data only into the regions we can’t hear which are the ones that sit under a perceptual threshold.


Both files were generated by Resemble. One has the PerTh watermark applied; the other does not. The difference is imperceptible — exactly the point.