A groundbreaking approach to deepfake detection that combines efficient architecture with unparalleled accuracy across diverse languages and generation methods.
As generative AI evolves, so does the sophistication of synthetic audio. DETECT-2B builds on the foundation of our original Detect model with an ensemble architecture, self-supervised representation learning, and advanced sequence modeling — robust enough to spot deepfakes in the wild.
Multiple complementary sub-models are fused into a single prediction. Each captures a different signal — from low-level acoustic artifacts to high-level sequential patterns indicative of synthesis.
Pre-trained audio representation models like Wav2Vec2 give DETECT-2B a rich foundation of language-agnostic features, learned from massive amounts of unlabeled audio.
Adaptation modules inserted into key layers of a frozen backbone learn to shift attention toward subtle deepfake artifacts — without retraining from scratch.
State Space Models bring probabilistic temporal dynamics to the classifier, adapting to observed audio features and surfacing inconsistencies traditional classifiers miss.
Each sub-model predicts a fakeness score for short time slices across the duration of an input audio clip. Scores are aggregated and compared to a carefully tuned threshold to produce a final real-vs-fake classification.
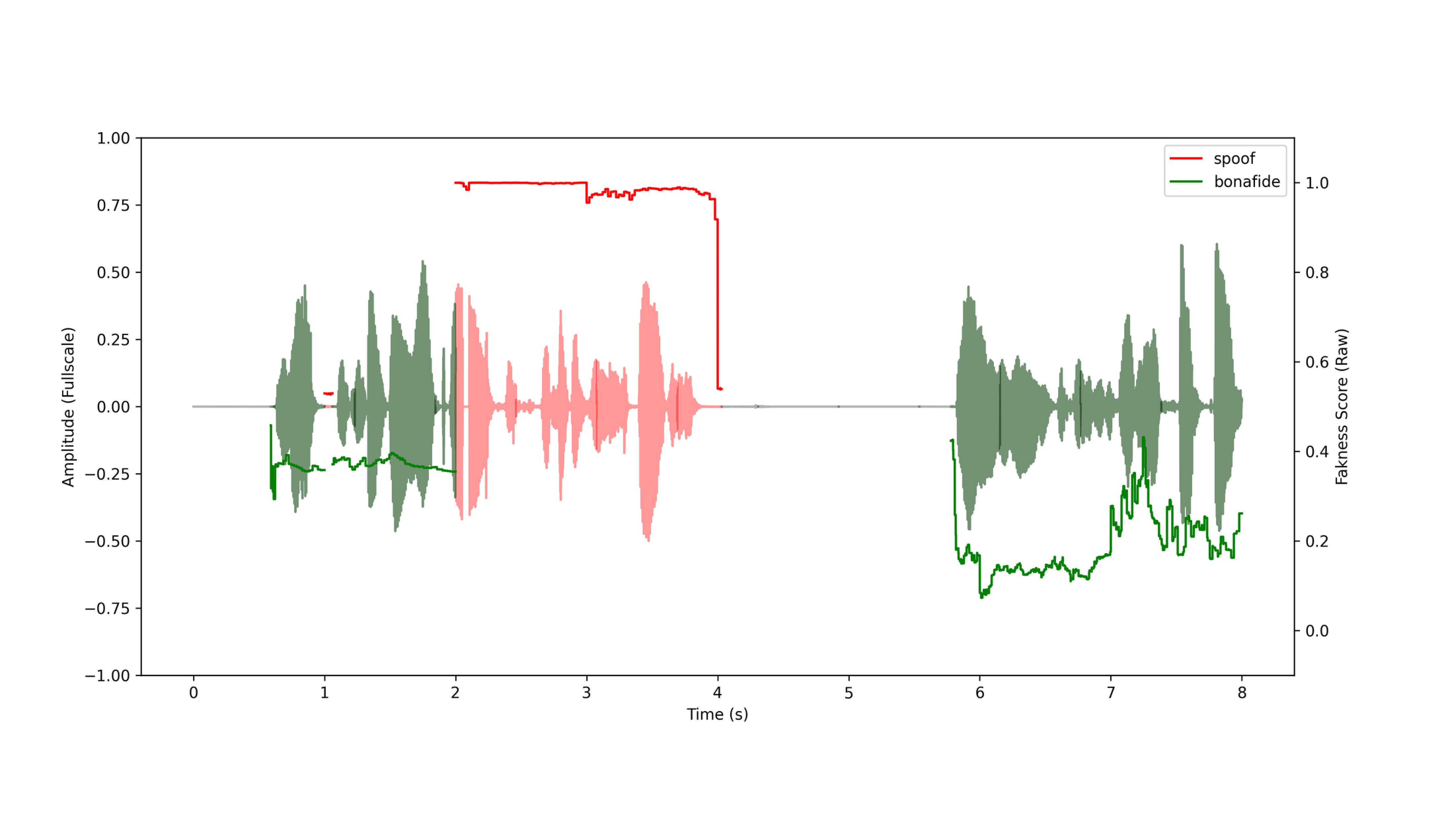
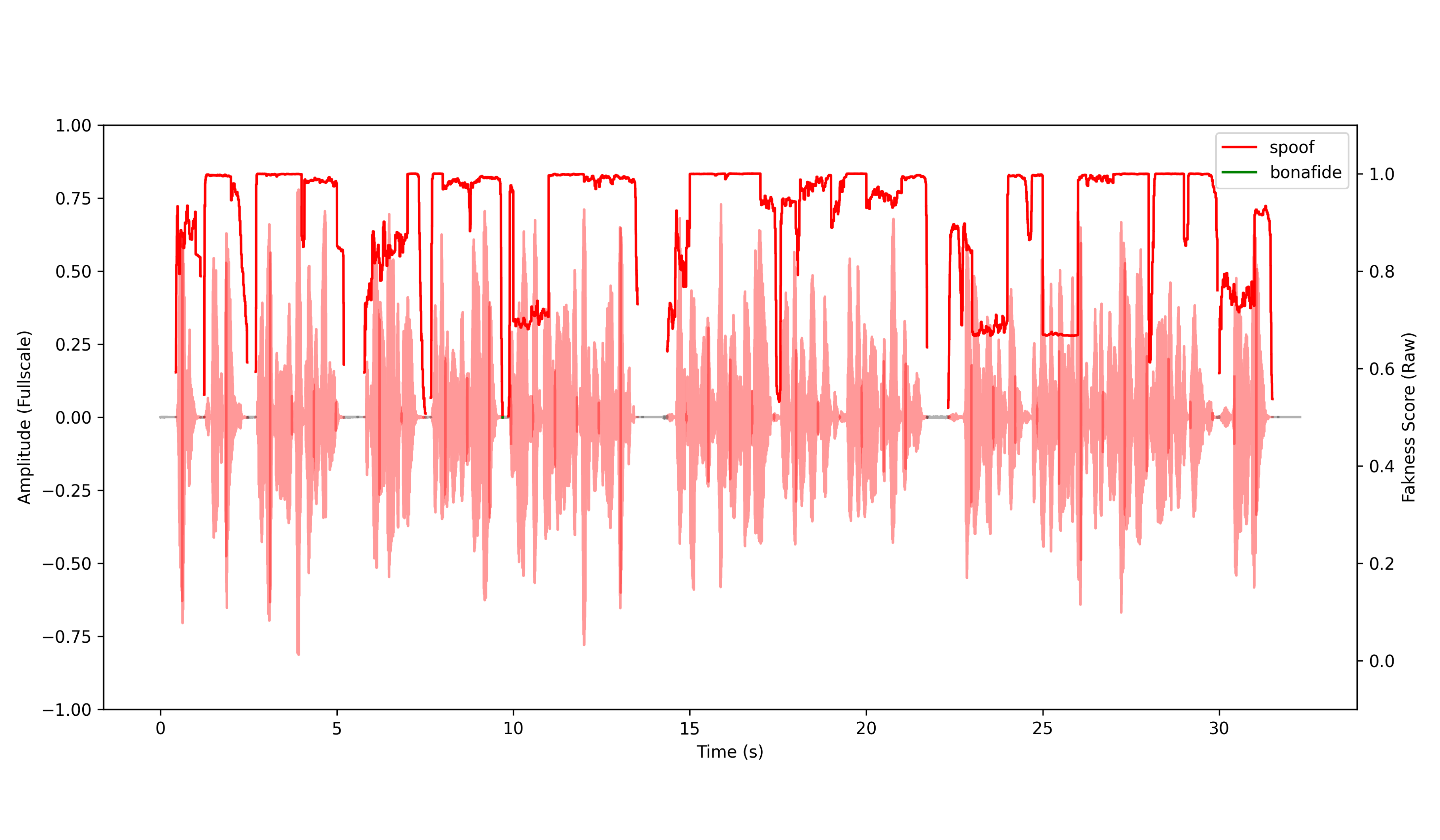
DETECT-2B doesn't just return a single pass/fail. Output is a granular, frame-by-frame analysis of the audio stream, with predictions made for each frame to determine whether it is a spoof.
The raw fakeness scores can be returned directly, or the API can aggregate them and apply the classification threshold to produce a single overall prediction — tunable to your tolerance for false positives and false negatives.
By leveraging pre-trained components and efficient fine-tuning techniques, DETECT-2B achieves state-of-the-art performance while staying relatively fast to train and lightweight to deploy.
That means sub-second inference — fast enough to drop into real-time audio pipelines, contact centers, and content moderation systems.
Our evaluation set is intentionally adversarial: unseen speakers, unseen deepfake generation methods, and languages the model never trained on — sourced from academic datasets and diverse real-world audio.
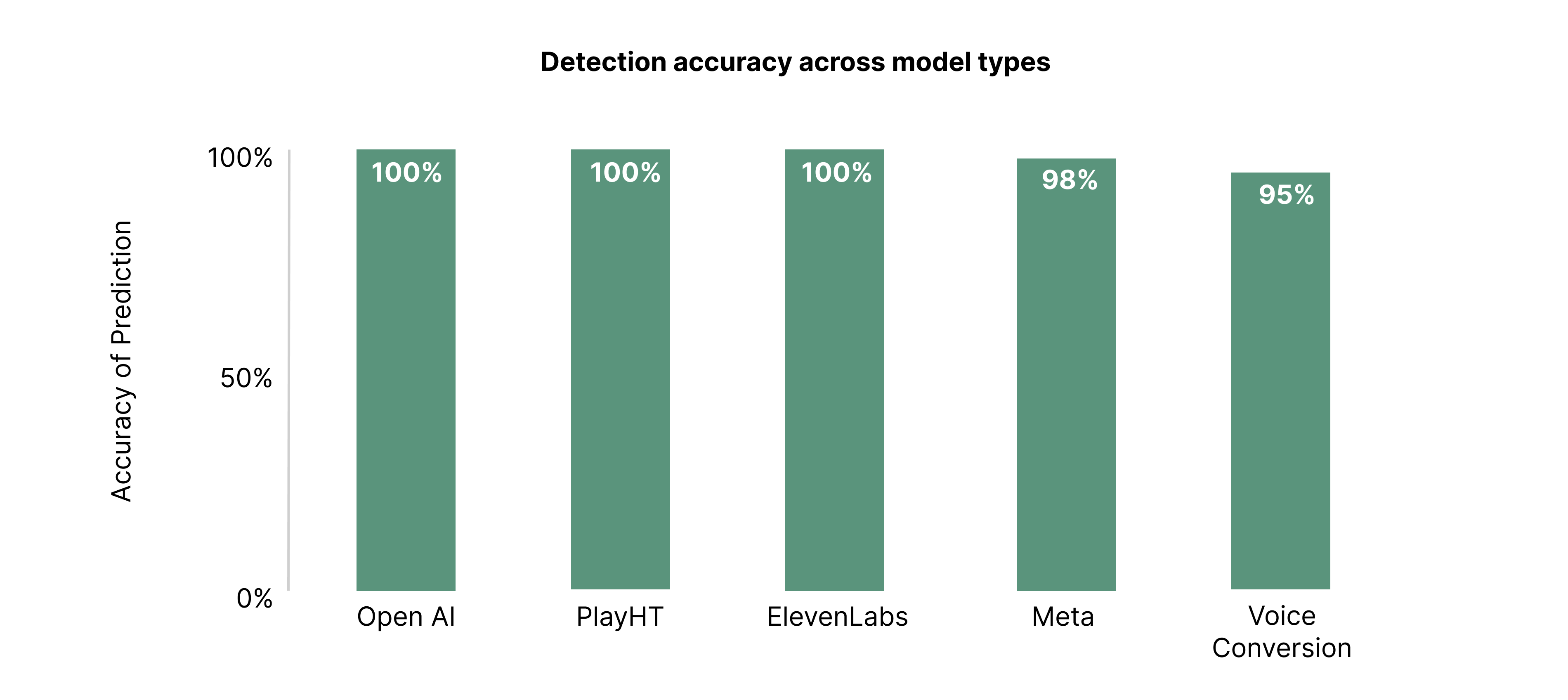
DETECT-2B achieves an impressive EER — correctly identifying the vast majority of deepfakes while maintaining a very low false positive rate. A substantial improvement over the original Detect model.
Consistently high accuracy across a wide variety of languages, including those not seen during training. The model is learning language-agnostic cues of audio manipulation.
Strong performance on the latest synthetic audio approaches — even methods not represented in training data. It's learning the fundamentals of synthesis, not memorizing patterns.

Whenever voice carries trust — in the contact center, in media, in communications — DETECT-2B helps verify that what you're hearing is real.
Screen inbound calls for synthetic voices before they reach an agent — blocking cloning-based fraud in real time.
Add a deepfake check to the editorial workflow. Upload a clip, get a granular fakeness score, make a confident call.
Batch-analyze user-uploaded audio through the API to surface manipulated content for review without blocking legitimate uploads.
Layer DETECT-2B into executive communications, wire-transfer approvals, and sensitive voice workflows as an extra line of defense.
Two ways to integrate DETECT-2B: a lightweight REST API for pipelines at scale, or a web-based dashboard for teams who want a visual interface.
Submit audio clips individually or in batches. Receive raw frame-level fakeness scores or a single aggregated prediction. Classification thresholds are adjustable to balance false positives and false negatives for your use case.
# Analyze an audio clip POST https://app.resemble.ai/api/v2/detect Authorization: Bearer <token> Content-Type: multipart/form-data file=@clip.wavRequest API access
For customers who prefer visual interaction: upload audio files, view frame-by-frame analysis, and adjust detection settings — no API work required. Ideal for trust & safety teams and editorial reviewers.
# What you get in the dashboard - Drag-and-drop audio upload - Frame-by-frame fakeness timeline - Per-language breakdowns - Adjustable classification threshold - Team sharing & audit historyBook a dashboard demo