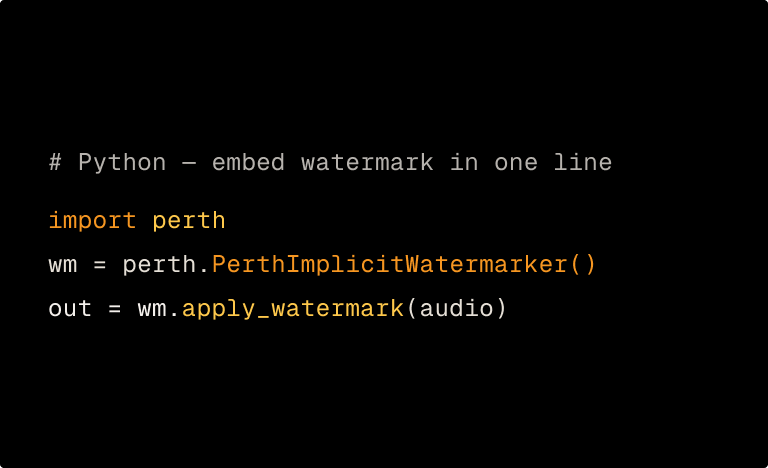
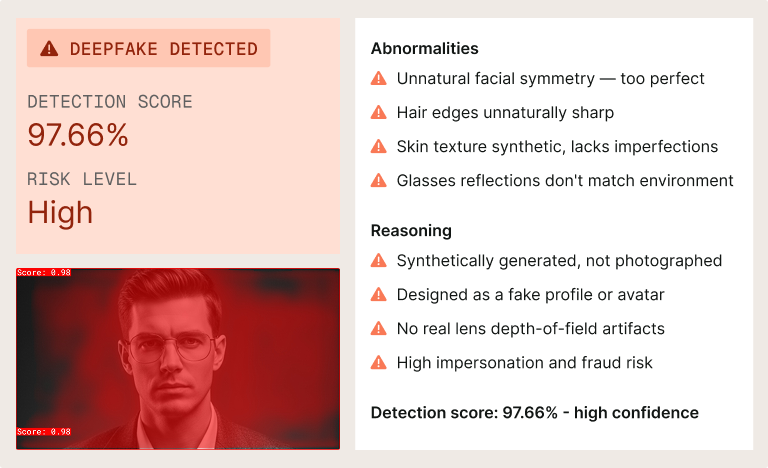
PerTh Multimodal extends our neural watermarking architecture beyond audio to cover video, image, and text with one API call. It encodes explicit marks and reads C2PA and SynthID.
The tools to create convincing synthetic content now require almost no technical skill. EU AI Act Article 50 requires machine-readable marking of AI-generated content by August 2026. PerTh Multimodal embeds an invisible, persistent watermark at creation across audio, video, image, and text so the proof of origin travels with the content.
Ownership embedded at creation
PerTh Multimodal embeds a data payload into perceptually masked regions of the signal. Inaudible in audio, imperceptible in image and video, semantically neutral in text. Add a custom identifier and it travels with the content.
Withstand real-world handling
The payload persists through format conversion, re-encoding, compression, and editing. PerTh Multimodal is trained against the transformations content encounters in the real world.
Verify on demand
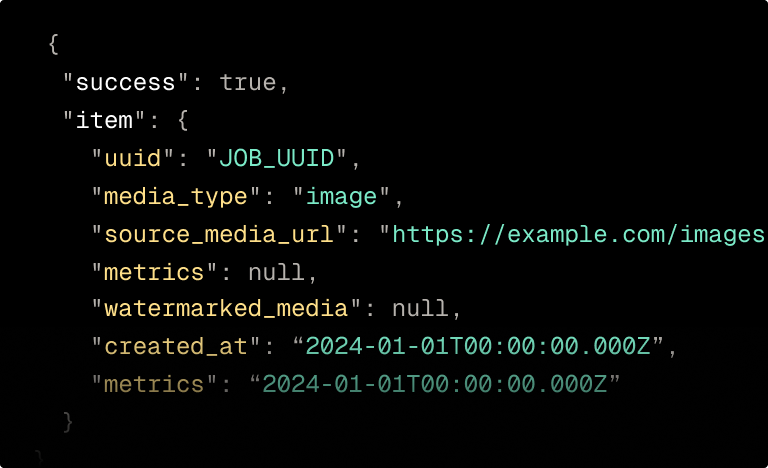
Run any file through the decoder and PerTh Multimodal returns your custom identifier, C2PA signatures, and SynthID in a single provenance report.
The same perceptual masking principles that made PerTh work for audio, now applies to video, image, and text with explicit payloads, so every file carries a verifiable identifier.
PerTh Multimodal's architecture applies the core insight of the original PerTh model — encode data only into the regions humans can't perceive, to four modalities, each with signal-appropriate algorithms.