

Synthetic media is now good enough that the question "is this real?" has become genuinely hard to answer. The EU AI Act's response to that problem is Article 50: all AI-generated media must be marked in a machine-readable format by 2 August 2026. Research published at ACM in 2025 found that only 38% of AI generators currently implement adequate watermarking. How generative model companies and enterprises operate and how regulators want them to operate is quite far apart.
PerTh Multimodal is how we decided to serve the creators and enterprises that need to watermark audio, video, image, and text coverage with a single API - for their own IP protection and for current and future regulation.
When PerTh shipped in 2023, it was an audio-only watermarker. The community picked it up fast with hundreds ofGitHub stars, enterprises running it in production pipelines, and a base of open source users building on top of it. But the team had been documenting its limitations honestly: four attack categories consistently degraded watermark recovery in ways that mattered in production and the coverage was always narrower than the compliance problem it was meant to solve. PerTh Multimodal is the ground-up rebuild, and the rest of this post explains exactly how it fixes each limitation.
This post is written for engineers who want to understand what changed and why the design decisions were made the way they were. If you want the short version: PerTh Multimodal achieves near-100% accuracy on all internal audio metrics; expands coverage to video, image, and text; improves performance for custom watermark payloads; and ships with ONNX support for edge and mobile deployment.
What is PerTh?
PerTh, short for "perceptual threshold" , started as a name for a specific idea: embed watermark data inside the regions of audio that sit below what the human ear can detect. For PerTh Multimodal, that name describes a family of models with the same design goal across audio, video, image, and text: embed an imperceptible, tamper-resistant signature that survives whatever the content goes through after it leaves your pipeline.
Each PerTh modality uses two models bundled together:
- An encoder that adds an imperceptible signature to the input media
- A decoder that recovers that signature from any downstream copy
What differs across modalities is what “imperceptible” means for each medium, and which domain the encoder and decoder operate in.
PerTh Multimodal modality coverage at a glance:
How each modality works
Audio: Psychoacoustics as the encoding channel
Human hearing has uneven sensitivity across frequencies, and a louder sound at one frequency creates a masking effect that hides quieter nearby sounds. PerTh places watermark data inside those masked regions, the ones a listener's ear never registers.
Both the encoder and decoder operate in spectral space, modifying frequency content directly via a residual additive mask on the magnitude spectrogram. The architecture does this in the frequency domain rather than the waveform domain for several reasons:
- Waveform-level models have high-bitrate output which can increase latency
- Restricting the additive mask to low-frequency spectrogram regions lets PerTh guarantee perfect reconstruction of high-frequency content, something a waveform-level model typically cannot guarantee
- Restricting the additive mask to low-frequency spectrogram regions also ensures the watermark is difficult to remove without distorting the underlying speech content
That encoder-decoder pair comes in two variants depending on what you need to embed. Implicit models encode a single bit, the decoder predicts whether a watermark is present or absent, no payload argument needed. Explicit models allow a custom bit-string of fixed length to be embedded and later recovered.
Image and video: Better than open source baselines
The image and video models use a pixel-level encoding approach following similar techniques to Google’s SynthID and Meta’s Videoseal, where the encoder makes imperceptible modifications to pixel values to carry the watermark payload. The decoder knows the pattern to look for and can recover the payload from a modified copy.
The main difference is Google extended SynthID to a small number of invited partners whereas PerTh Multimodal is available to any organisation via API, today, without a selection process. Using a mixture of in-house architectures, data, and methods, we have been able to demonstrate high robustness across a wide range of data augmentations. Benchmark data comparing PerTh Multimodal against a Videoseal baseline is available.
Text: Watermarking through linguistic rewriting
Text watermarking works differently from the signal-level approaches used for audio, image, and video. An encoding model rewrites the input text with subtle changes like different word choices or minor structural variations that carry the watermark pattern. The output says the same thing; the pattern of changes is the watermark. When the text is later submitted to the decoder, it looks for its own linguistic signature to determine whether it authored the content.
What the PerTh V1 Audio Model Got Wrong and How PerTh Multimodal Fixes it
The V1 limitations were specific and documented. Four attack categories consistently degraded watermark recovery:
- Waveform pitch shifting
- Waveform low-pass filters
- Additive noise
- Contiguous spectral band masking / Notch filters
None of these are exotic attacks — pitch shifting is standard in audio production, low-pass filtering is applied by default in many encoding pipelines, and additive noise is present in the majority of real-world recordings. An attacker who understood V1's architecture could apply any of them and meaningfully degrade watermark recovery without destroying the underlying audio.
PerTh Multimodal was rebuilt to address each failure mode through a completely new training attack system and a redesigned training curriculum. For image and video, the augmentation suite covers spatial and colour-domain transformations including brightness, colour jitter, crop, blur, JPEG compression, resizing, and many more transformations most likely to be applied to visual content in production environments.
The PerTh Multimodal Training Attack System
The fundamental challenge in building a robust watermarker: the decoder has to be trained on augmented (“attacked”) data, as well as clean data. Before the decoder sees the watermarked signal, augmentations are applied (compression, filtering, pitch shifting, re-encoding, and many others) and the decoder learns to recover the watermark from a signal that has already been degraded.
The constraint that makes this technically hard: those augmentations must be differentiable, or approximately so, for gradients to flow back through training. Arbitrary signal processing cannot be used as a training augmentation without careful design.
PerTh Multimodal solves this with a library of stable augmentations built for the spectral, waveform, and image domains, which all produce usable gradients or have stable dynamics with straight-through estimation.
Examples of spectral attacks used:
- Gaussian Noise
- Scaling
- Low-clip / High-clip
- Quantization
- Band Masking
- Time Masking
- Reverb
Examples of waveform attacks used:
- Precision Reduction
- Mu-law Compression
- Dithering
- Gaussian Noise
- Wavelet Noise
Examples of image/video attacks used:
- Various Codec / Compression Round-trips
- Rotation, Scaling, Stretching, Cropping, etc
- Quantization
- Noising (Salt & Pepper, Gaussian, etc)
- Filters / Effects (Brightness, Shadows, Sharpness, etc)
This is a subset of the full augmentation library, which is constantly expanding.
The breadth matters because diversity of training attacks is how robustness generalizes. Researchers benchmarking watermarkers at Interspeech 2025 found that neural compression posed the most significant challenge even for models trained with compression augmentation and that attack diversity improves robustness, but is insufficient on its own. PerTh Multimodal’s design responds to exactly that finding: attack diversity plus curriculum design, not either alone.
The Training Curriculum: Hard-Example Mining and Adaptive Batching
Attack diversity gets you coverage. What determines whether the model actually generalises to hard attacks is how the training curriculum evolves once those attacks are in the mix.
Standard training applies augmentations with fixed weights throughout the run. Once a model gets accurate on easy attacks, it keeps seeing them at the same rate as hard ones.
PerTh Multimodal introduces train-time hard-example mining. The model is periodically evaluated against held-out data, with accuracy measured per attack type. Attack categories with poor evaluation accuracy get higher weights in the random augmentation selection. The training distribution adapts to wherever the current weaknesses are.
Adaptive batch scheduling runs alongside this. Larger batch sizes late in training produce smoother gradients and improve convergence. PerTh Multimodal automates this with a batch_schedule hyperparameter that increases batch size over time, automatically configuring dataloaders and gradient accumulation within a defined VRAM budget. Learning rate scheduling was removed — smoother gradients from larger batches made it redundant, and it was observed to introduce instability in some training runs.
Decoding Thresholds: What the Numbers Mean for Your Integration
Watermark decoding is probabilistic. Under ideal conditions, a 16-bit PerTh audio watermark has a bit recovery probability above 97%. The practical question for integration is: how many bits need to match before declaring a watermark detected?
That threshold is a tradeoff between detection rate and false positive rate. Let ‘k’ represent the number of bits that must match to declare a watermark detection.
The table above shows possible threshold choices, and the trade-offs that result from them. Two setups cover most real-world use cases:
Threshold 13 is the recommended default. 99.9% detection rate, roughly 1% chance a random bit string triggers a false positive. The right choice when missing a real watermark is the higher cost.
Threshold 14 is better when false positives carry legal or regulatory consequences such as rights enforcement filings or court-ready evidence packages.
There are two main limitations to understand upfront:
- Traditional digital signatures are not compatible with probabilistic decoding. PerTh recovers a random subset of bits, which limits cryptographic constructions. The watermark message payloads are effectively public information. PerTh's security model rests on making watermark removal difficult, not on hiding the payload contents. For deployments requiring strong cryptographic ownership guarantees, a custom per-user model is the appropriate solution.
- Attack robustness is much lower for the explicit 16-bit watermark model. Under some conditions, per-bit accuracy may be below 80% on average. The implicit (1-bit) watermarker does not suffer from this limitation.
Performance Benchmarks - Open Source Baseline Comparison, Resilience to Attack Types, Latency and Memory
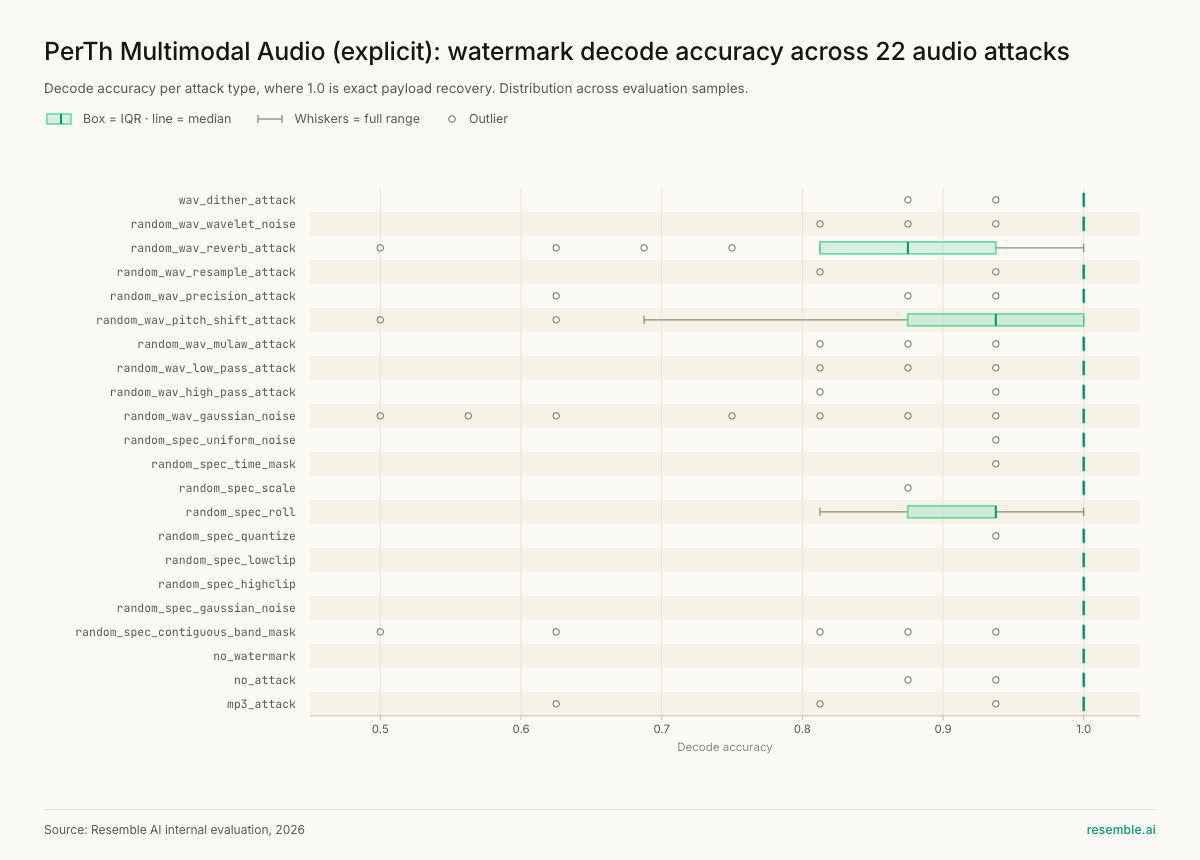
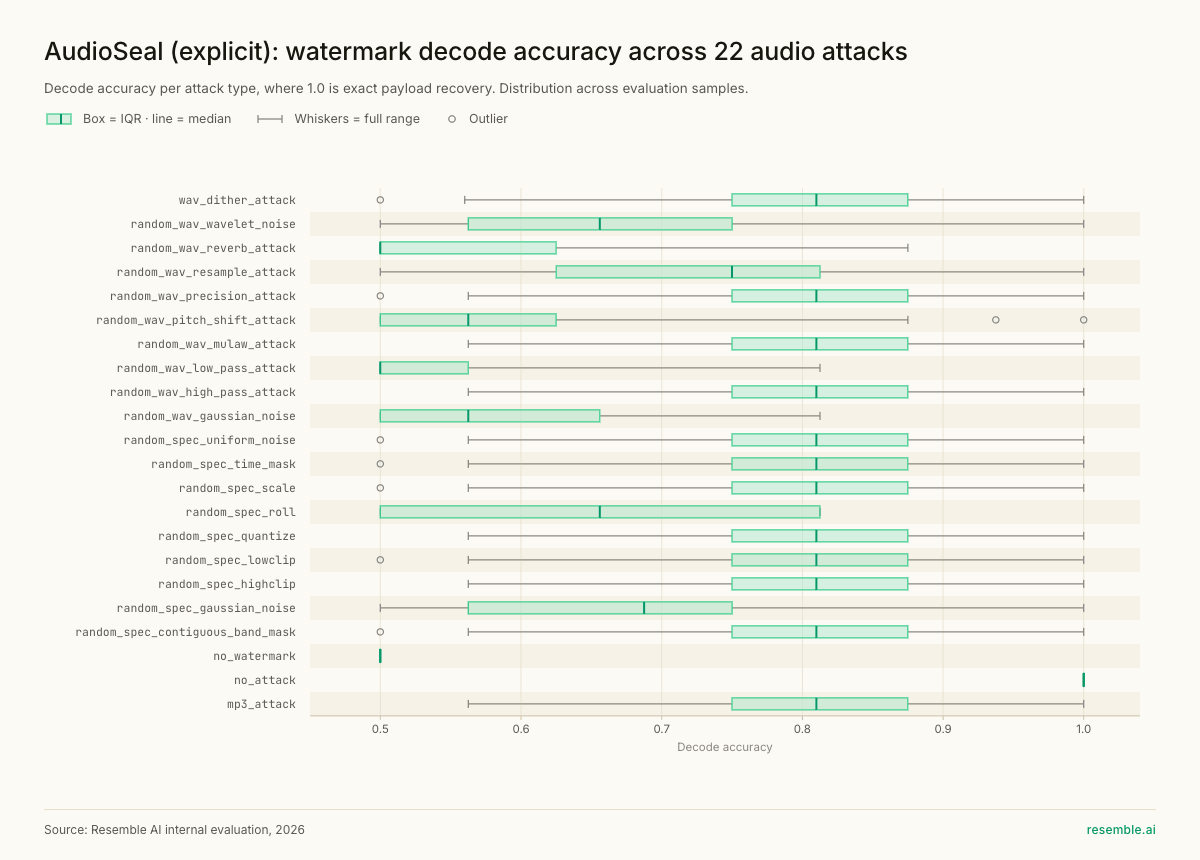
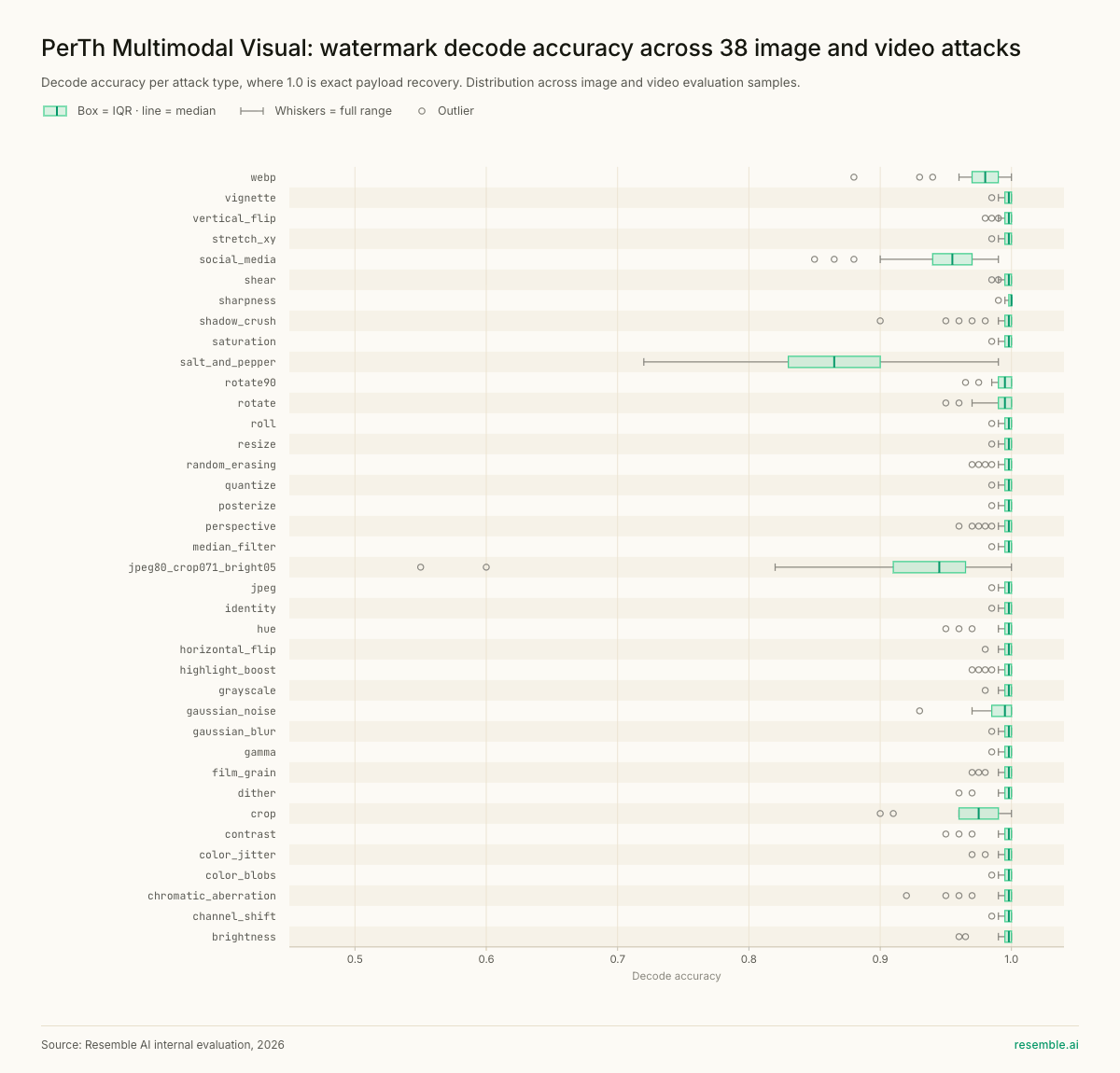
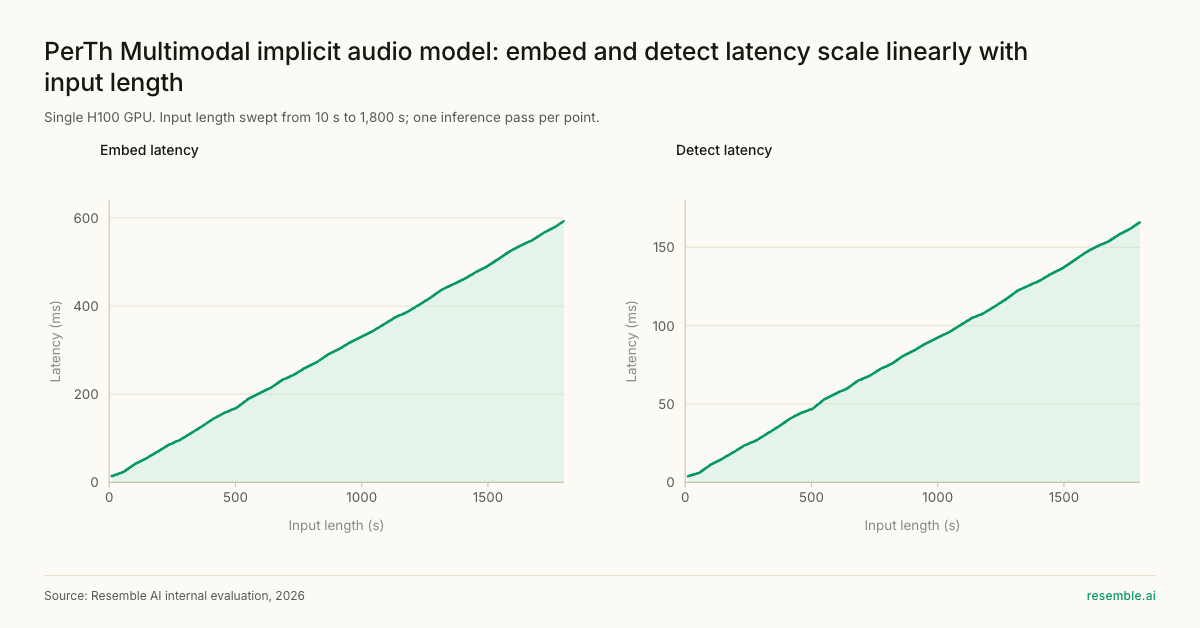
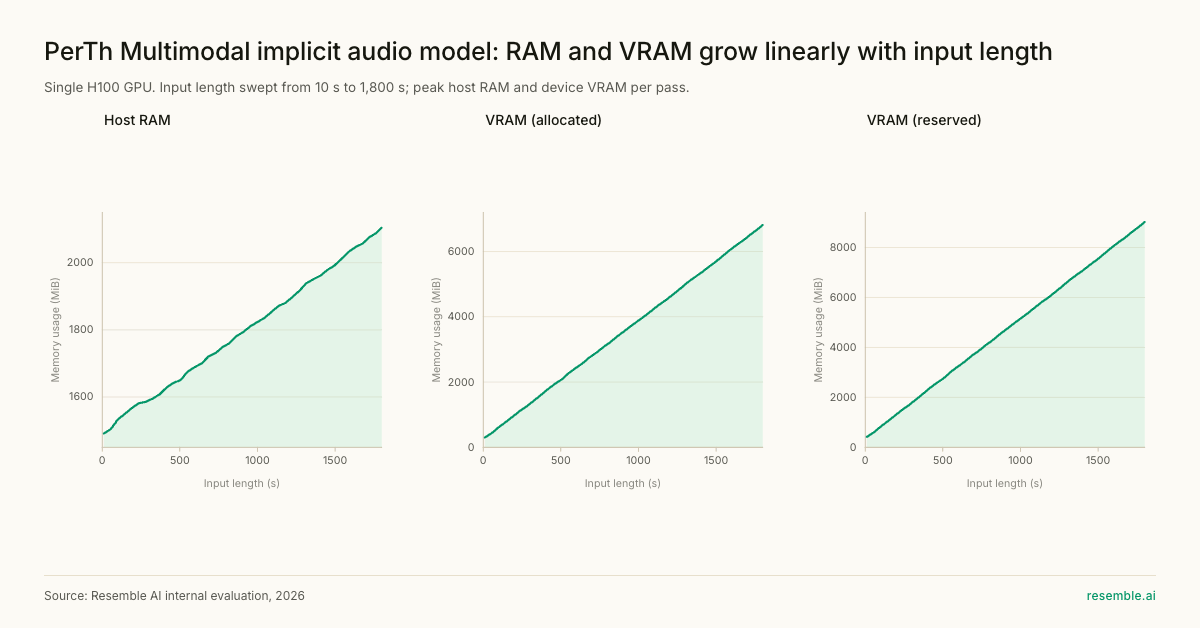
Edge Deployment: ONNX Built In
Because PerTh Multimodal’s modules are compatible with standard ONNX op-sets, converting for mobile or edge deployment is straightforward across all modalities.The implicit audio model variant has been validated down to 500ms input chunk sizes, covering streaming and real-time edge deployment. The explicit audio model variant requires larger chunk sizes due to the higher message bitrate, so the choice of chunk size impacts performance and accuracy. For the explicit model, chunk sizes up to 2 seconds are required for high accuracy.
What the EU AI Act Means for Teams Evaluating Watermarking Right Now
Article 50 of the EU AI Act requires that AI-generated audio, video, image, or text be marked in a machine-readable format, with full enforcement from 2 August 2026. The December 2025 draft Code of Practice moves from principle-based guidance to specific technical requirements, mandating a multilayered approach that includes imperceptible watermarks embedded into content and surviving compression and editing.
The Commission's March 2026 guidance frames those requirements in engineering terms: solutions must be "effective, interoperable, robust, and reliable." The training attack system is what makes the robustness requirement concrete — diverse augmentations that push the decoder to generalise rather than memorise. ONNX support handles interoperability. The threshold table above gives compliance teams the quantitative handles to demonstrate reliable performance to regulators.
PerTh Multimodal also pairs with C2PA for dual-layer provenance: C2PA handles file-level metadata (who created it, when, with which system), while PerTh Multimodal handles the signal-level watermark that survives re-encoding and format conversion after metadata has been stripped. A March 2026 paper highlighted potential conflicts between C2PA manifests and invisible watermarks when treated as competing mechanisms, so using them as complementary layers (which is how PerTh is designed) avoids that conflict.
Evaluating PerTh Multimodal for a compliance use case? Explore Resemble Watermarker
What Has Not Been Evaluated Yet
Three areas remain under active evaluation:
Non-speech audio. PerTh Multimodal is trained and evaluated on speech datasets. Background music and environmental audio is out-of-distribution for current models. Generalization to non-speech content is untested.
Real-world case studies of explicit watermarking. Given the limitations in decoding performance, we are looking for parties interested in evaluating the explicit watermarking model. This would provide more clear data surrounding accuracy and use-cases.
Getting Started
View the API documentation at https://docs.resemble.ai/detect/watermark
For teams evaluating PerTh for a production pipeline or EU AI Act compliance use case, explore Resemble Watermarker or talk to the team


