

Audio surrounds daily life, calls, meetings, alerts, and ambient sounds, all carrying subtle patterns that often go unnoticed. AI-powered audio detection converts this continuous stream into actionable insights, enabling organizations to identify security threats, monitor operations, and analyze customer interactions in real time.
Research indicates that AI-driven audio recognition is expanding rapidly, with adoption projected to grow over 15.83% annually, highlighting its increasing relevance across industries.
By analyzing tone, frequency, and acoustic patterns, these systems convert everyday sound into actionable intelligence. This enables informed, data-driven decisions while enhancing operational effectiveness across various applications.
At a Glance:
- AI can identify and classify sounds, converting everyday audio into actionable insights for applications in security, healthcare, customer service, and media.
- Audio signals are processed using feature extraction methods like FFT and MFCC, then categorized with machine learning models for accurate analysis.
- Deep learning models, including CNNs, RNNs, and transformers, can detect complex audio patterns and adapt to new or unusual sounds.
- AI-powered audio detection is applied in gunshot detection, respiratory health monitoring, sentiment analysis during calls, and media content moderation.
- Challenges such as background noise, data privacy, model limitations, and potential misuse require robust safeguards, diverse datasets, and ethical oversight.
- Resemble AI enhances detection by providing real-time deepfake identification, AI watermarking, secure voice verification, explainable insights, and protections for ethical audio use.
Understanding Audio Detection
Audio detection is the process of identifying and analyzing sound signals to classify them into meaningful categories, crucial for applications like security monitoring, medical diagnostics, and human-computer interaction.
For instance, a smart home security system must distinguish a glass-breaking sound from everyday household noises to trigger alerts or record accurately. Achieving this level of precision relies on the key components:
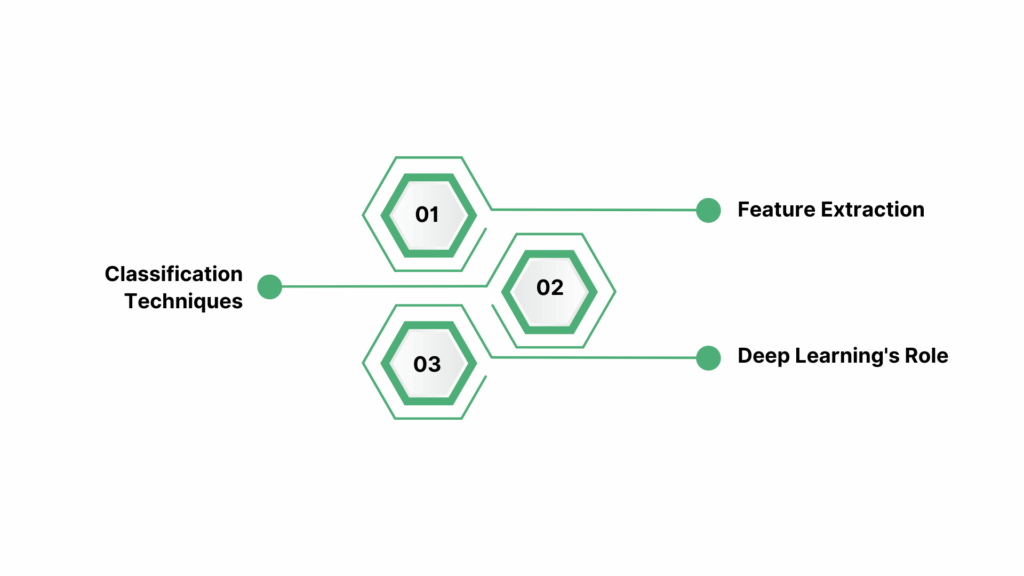
1. Feature Extraction
This initial step involves transforming raw audio signals into structured data by isolating relevant characteristics. Techniques such as Fast Fourier Transform (FFT) and Mel-frequency cepstral coefficients (MFCCs) are commonly employed to capture the frequency and temporal aspects of sound.
2. Classification Techniques
After feature extraction, machine learning algorithms are applied to categorize the audio signals. Standard methods include Support Vector Machines (SVM), K-Nearest Neighbors (KNN), and Random Forests, which are trained on labeled datasets to recognize patterns and make predictions.
3. Deep Learning's Role
Deep learning models, particularly Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs), have significantly enhanced the accuracy and efficiency of audio detection systems.
These models can automatically learn hierarchical features from raw audio data, reducing the need for manual feature engineering and improving performance in complex tasks.
Protect your organization from audio deepfakes and voice-based fraud with Resemble Detect. This AI-powered solution monitors audio in real time, identifying subtle anomalies to catch cloned voices, synthetic speech, and unauthorized content before they create risks.
These core components are brought to life through a range of technologies that process, analyze, and interpret audio signals with increasing accuracy and efficiency.
Technologies Powering Audio Detection
Understanding the technologies behind audio detection helps reveal why some systems outperform others and where they can be applied effectively. These tools go beyond merely “hearing” sound; they interpret patterns, context, and meaning, enabling smarter decision-making in security, customer service, and analytics.
Key technologies include:
- Machine Learning Models: CNNs and RNNs detect patterns in audio signals, distinguishing subtle variations in pitch, timbre, and rhythm.
- Multimodal Integration: Combines audio with other data types like video or sensor inputs for more comprehensive analysis.
- Natural Language Processing (NLP): Extracts meaning from speech, enabling understanding of context, intent, and semantics.
Also Read: 4 Ways to Detect and Verify AI-generated Deepfake Audio
These technologies form the foundation for practical applications, turning raw audio data into actionable insights across industries.
Applications of AI-Powered Audio Detection
AI-powered audio detection is no longer confined to research labs; it is actively shaping how organizations monitor environments, assess health, understand customer interactions, and manage media content.
Their applications span security, healthcare, customer service, and media, helping organizations act quickly and make better-informed decisions.
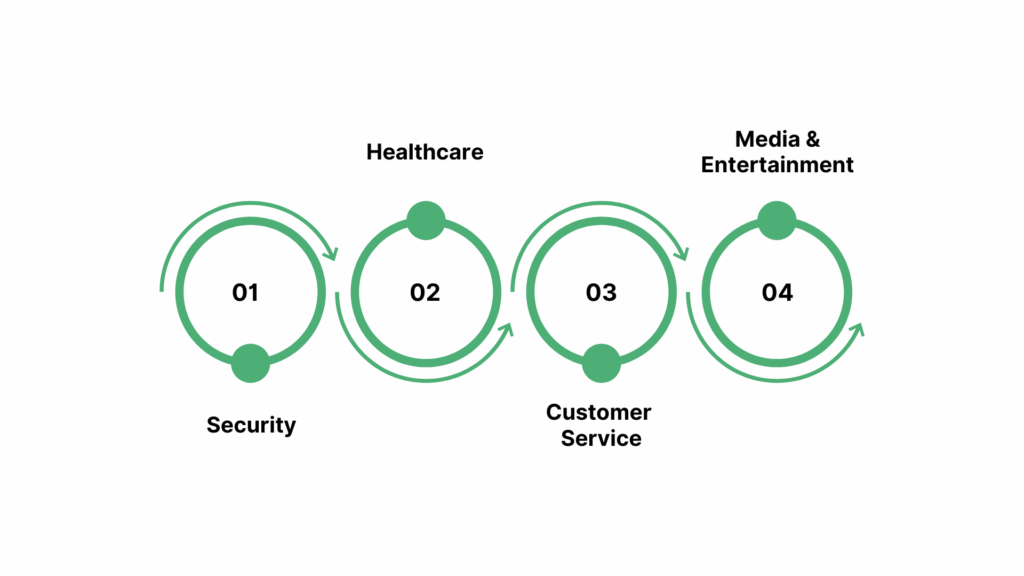
1. Security
AI-driven gunshot detection systems analyze acoustic signals to identify firearm discharges in real-time. For instance, Flock Safety's technology has been implemented in cities like San Jose, where it achieved an 81% confirmation rate for gunshot alerts after recalibration.
Similarly, Purdue Northwest researchers have developed audio coding algorithms to test acoustic sensors without disrupting daily activities, ensuring optimal functionality in sensitive environments like hospitals and airports.
2. Healthcare
In the medical field, AI models analyze cough sounds to detect respiratory conditions such as tuberculosis. Salcit Technologies' Swaasa® platform utilizes AI to assess lung health by analyzing cough sounds, aiding in early disease detection.
Additionally, Google's Health Acoustic Representations (HeAR) model uses smartphone microphones to identify patterns in cough and breath sounds, facilitating remote monitoring of respiratory diseases.
3. Customer Service
AI-powered sentiment analysis tools are transforming customer service operations by evaluating the emotional tone of voice interactions. Platforms like Azure AI employ machine learning algorithms to assess customer sentiments, positive, negative, or neutral, during calls.
This analysis helps in understanding customer emotions, improving agent performance, and enhancing overall customer experience.
4. Media & Entertainment
In the media industry, AI technologies are employed for content moderation and audio-based search functionalities. Amazon Rekognition Content Moderation utilizes machine learning to analyze videos and images, detecting inappropriate content and ensuring compliance with community standards.
While AI-powered audio detection offers powerful insights across industries, it also faces technical limitations and practical hurdles that must be carefully managed.
Challenges in Audio Detection
Despite its potential, AI-powered audio detection faces practical and ethical hurdles that can affect reliability, accuracy, and compliance. Background noise, data privacy concerns, and model limitations are common obstacles.
Understanding these challenges and their solutions is crucial for effective, responsible deployment.
| Challenge | Impact | Workarounds / Solutions |
| Noise Handling | Background sounds reduce detection accuracy and increase false positives. | Noise reduction, directional mics, robust feature extraction (MFCC, spectral subtraction), training on noisy datasets. |
| Data Privacy & Compliance | Processing voice data may violate GDPR, HIPAA, or local laws. | Anonymize/encrypt audio, obtain consent, follow data protection rules, and secure storage. |
| Model Generalization | Models may fail with new accents, languages, or environments. | Train on diverse datasets, use transfer learning, and update models with real-world data. |
| Computational Load | Real-time, high-res audio analysis can strain resources. | Optimize models, edge computing, and efficient signal processing. |
| Ethical Misuse | Misapplication for surveillance or monitoring raises ethical concerns. | Restrict access, implement ethical guidelines, and ensure transparency. |
Addressing these challenges requires advanced approaches that combine robust algorithms, high-quality data, and adaptable tools to enhance accuracy and reliability in audio detection.
Also Read: How to Detect Deepfakes Using AI
How Resemble AI Enhances AI-Powered Audio Detection
Modern audio ecosystems demand more than detection; they require verification, interpretation, and ethical use at scale. Resemble AI extends the scope of audio analysis by combining detection models with real-time synthesis and authentication frameworks.
Its tools strengthen trust across voice-driven platforms, offering organizations precision control over identity, ownership, and integrity in every interaction. Here are Resemble AI’s key capabilities in audio detection and security:
- DETECT-2B Deepfake Detection: Uses a highly accurate ensemble model to identify synthetic audio across 30+ languages in milliseconds, leveraging self-supervised audio representation and efficient fine-tuning for real-time verification
- Deepfake Detection: Uses real-time multimodal analysis to identify manipulated audio by evaluating acoustic, linguistic, and visual cues simultaneously, ensuring authenticity in calls, recordings, and content.
- AI Watermarker: Embeds imperceptible, tamper-resistant markers into audio files to protect intellectual property and maintain traceability across distributed or generated sound assets.
- Identity: Enables secure voice enrollment and verification by capturing unique vocal signatures, supporting authentication in sensitive environments such as banking, healthcare, and enterprise communications.
- Audio Intelligence: Leverages explainable AI with an audio-enabled language model to highlight which audio features triggered alerts or classifications, providing transparency and actionable insights.
- Deepfake Detection for Meetings: Monitors live sessions on Meet, Teams, Zoom, and Webex to detect synthetic or impersonated voices in real time, without latency or manual intervention.
- Security Awareness Training: Utilizes Gen AI–based simulations to expose teams to realistic deepfake scenarios across calls and video meetings, enhancing their response to emerging voice-based threats.
Building on advanced tools for detection, verification, and explainable insights, the field of audio analysis is moving toward faster, more intelligent, and context-aware systems.
Future Trends in Audio Detection
Audio detection is becoming increasingly critical as synthetic and complex sounds emerge across industries. New technologies are improving how systems recognise, interpret, and act on these sounds.
Understanding these trends helps organizations respond faster, make sense of audio data, and reduce risks:
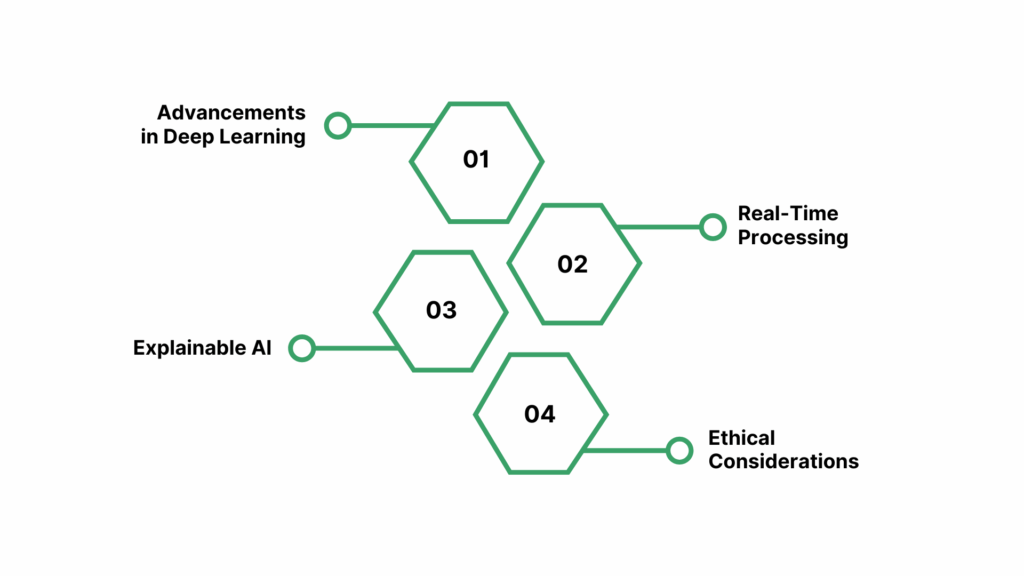
1. Advancements in Deep Learning
Transformer models are improving audio detection by capturing long-range dependencies in sound, outperforming traditional CNNs. Few-shot learning allows systems to adapt to new audio tasks with minimal labeled data, making it easier to handle rare or emerging audio patterns.
2. Real-Time Processing
Real-time analysis is increasingly critical for applications like live surveillance and voice assistants. Optimized deep learning models, often combined with digital signal processing techniques, ensure fast, accurate detection without overloading system resources.
3. Explainable AI
Transparency is becoming essential as audio models grow more complex. Explainable AI techniques highlight which audio features trigger specific classifications, building trust and accountability in sectors such as security and healthcare.
4. Ethical Considerations
Bias, fairness, and accountability remain major concerns in AI audio detection. Researchers are focusing on diverse training datasets, bias mitigation, and ethical frameworks to ensure systems operate fairly and responsibly across different populations.
Conclusion
Sound is all around us, but understanding it and knowing when it matters can make all the difference. With the right tools, you can spot anomalies, verify voices, and make sense of complex audio in real time.
Resemble AI puts this power in your hands, helping you take control of every audio interaction with clarity and confidence. It achieves this by safeguarding against misuse, detecting deepfakes and voice impersonation before they can create problems.
Curious to see it for yourself? Book a demo to explore how Resemble AI can benefit your team.
FAQs
1. What is AI-powered audio detection used for?
It allows organizations to interpret everyday sounds, turning them into actionable insights for security, healthcare, customer service, and media.
2. How does AI analyze audio signals?
AI extracts key features from audio and uses machine learning to classify and understand sounds accurately.
3. Why is deep learning important for audio detection?
Deep learning models, such as CNNs and transformers, can identify complex patterns and quickly adapt to new or unusual audio scenarios.
4. What challenges should leaders be aware of?
Background noise, privacy concerns, model limitations, and potential misuse require careful management and ethical safeguards.
5. How can Resemble AI support my organization?
It provides real-time deepfake detection, secure voice verification, AI watermarking, and clear, interpretable insights to manage audio safely and confidently.


