Chatterbox is MIT-licensed and open-source. Clone any voice from 10 seconds of audio, or generate one from a text description. PerTh watermarking available on every output.
What is the difference between Rapid Clone and Professional Clone?
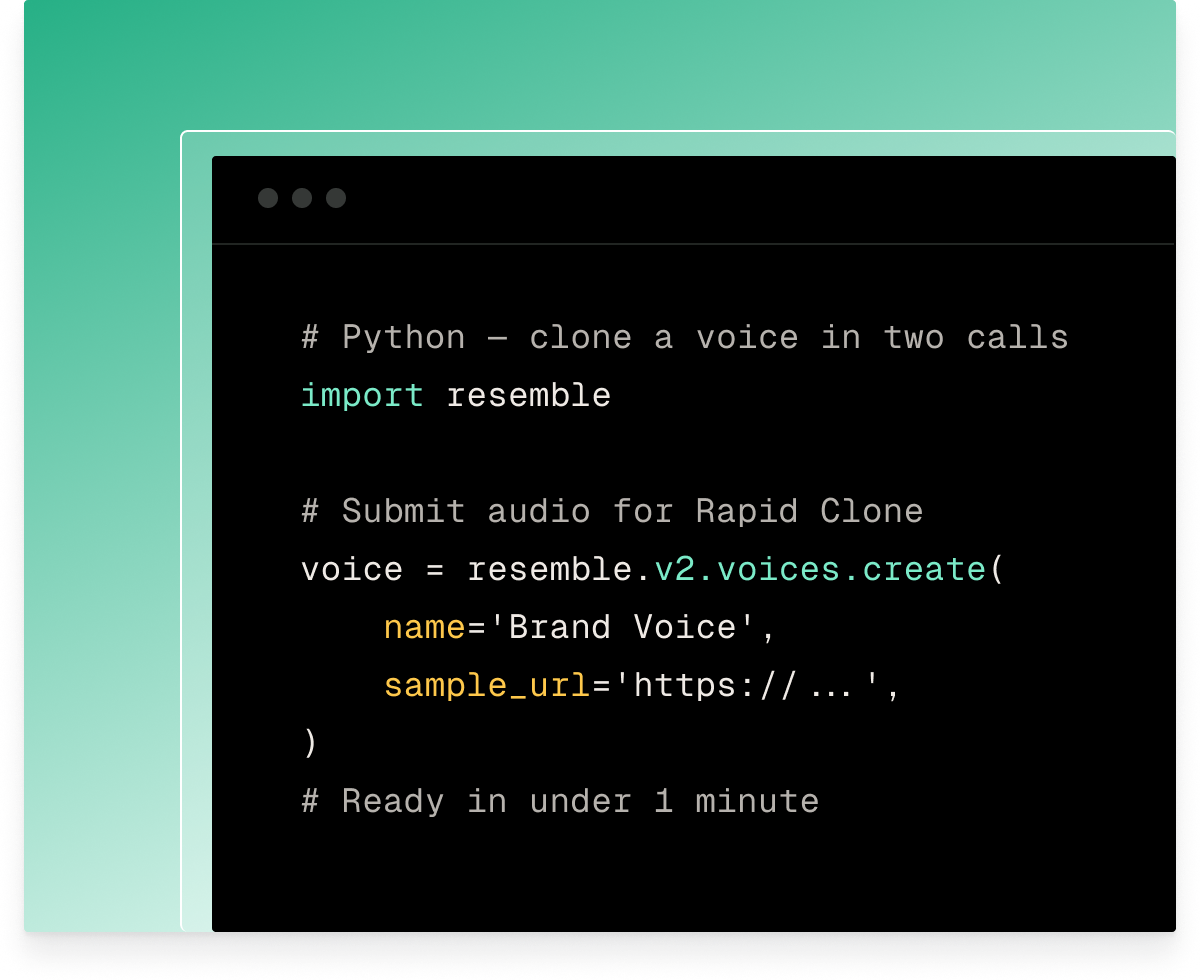
Rapid Clone needs 10 seconds, delivers in under 1 minute. Professional Clone needs 10 to 25+ minutes, trains in ~40 minutes, and produces a voice with full emotional range nearly indistinguishable from the source.
How does Voice Design work?
Describe the voice you want in natural language: age, accent, tone, style. The API returns 3 distinct candidates. Choose one and generate speech immediately, even while the voice finishes building in the background.
Can a cloned voice speak multiple languages?
Yes. Chatterbox Multilingual supports zero-shot cloning across 23 languages. Clone once in any language and generate speech across all 23 without separate training runs. Accent and vocal character are retained.
DIs consent required for voice cloning?
Yes for Professional Clone. Explicit verifiable consent from the voice talent is required before training data is uploaded. Consent workflows are built into the platform.
Can I create multiple variants of the same cloned voice?
Yes. Once a voice is cloned, prompt it in natural language for different use cases: conversational, commercial, phone agent, and more. Each variant is saved and reusable via API.
What are the deployment options?
Cloud API, open-source self-hosting via pip install, and on-premise via Docker/Kubernetes. Business plan or higher required for the Voice Cloning API. SLA documentation available on request.
How quickly can we integrate?
Most teams are live within a day using the REST API or SDK. Open-source deployment via Hugging Face requires no API key.
Get complete generative AI security
Join thousands of developers and enterprises securing with Resemble AI