

In 2026, global communications standards bodies reinforced how critical latency is for real-time voice systems, recommending that interactive voice applications maintain one-way delays below 150 milliseconds to preserve conversational quality and natural interaction.
/divi:paragraph divi:paragraphThis threshold reflects international telecom benchmarks for conversational speech quality, underscoring why low latency is not just a performance metric but a fundamental requirement for believable real-time voice AI experiences.
/divi:paragraph divi:paragraphFor voice conversion to truly feel real, whether transforming a user’s voice in a live game, a support call, or an accessibility tool, the system must respond within that tight latency window. Slow responses disrupt dialogue flow, break immersion, and erode user trust, turning what should be seamless interaction into noticeable delay that users instinctively reject.
/divi:paragraph divi:headingAt a Glance:
/divi:heading divi:list- divi:list-item
- Faster response equals higher trust. Real-time voice conversion only feels human when latency disappears from the conversation. divi:list-item
- Production systems fail on delay, not accuracy. Even high-quality voices break down if timing is off in live environments. divi:list-item
- Low latency unlocks real use cases. Customer support, gaming, accessibility, and secure communication depend on instant response. divi:list-item
- System design beats model tweaks. Sustainable low latency comes from architecture, infrastructure, and streaming-first decisions. divi:list-item
- The right platform reduces risk. Purpose-built real-time voice systems shorten time to production while maintaining reliability and ethics.
What Real-Time Voice Conversion Looks Like Under the Hood
/divi:heading divi:paragraphReal-time voice conversion changes how a voice sounds while speech is still happening, without altering the spoken content. It operates directly on live audio rather than pre-recorded files. At a system level, it works by:
/divi:paragraph divi:list- divi:list-item
- Processing streaming audio frames instead of full recordings divi:list-item
- Extracting voice characteristics such as tone and timbre in real time divi:list-item
- Applying a target voice profile on the fly divi:list-item
- Generating transformed audio continuously with minimal buffering
It is important to distinguish voice conversion from related technologies:
/divi:paragraph divi:list- divi:list-item
- Text-to-speech generates audio from text input divi:list-item
- Speech recognition converts speech into text divi:list-item
- Voice conversion modifies live audio while preserving the original words
Because every stage runs in a streaming pipeline, design decisions around frame size, model architecture, and synthesis speed directly affect performance. There is little room for delay, making real-time voice conversion one of the most latency-sensitive voice AI tasks.
/divi:paragraph divi:paragraphWhen implemented correctly, the transformation feels seamless and consistent, allowing voice experiences to function naturally in live, interactive environments.
/divi:paragraph divi:paragraphAlso Read: Real-Time Speech-to-Speech Conversion Technology
/divi:paragraph divi:headingThe Hidden Sources of Delay in Voice Conversion Pipelines
/divi:heading divi:image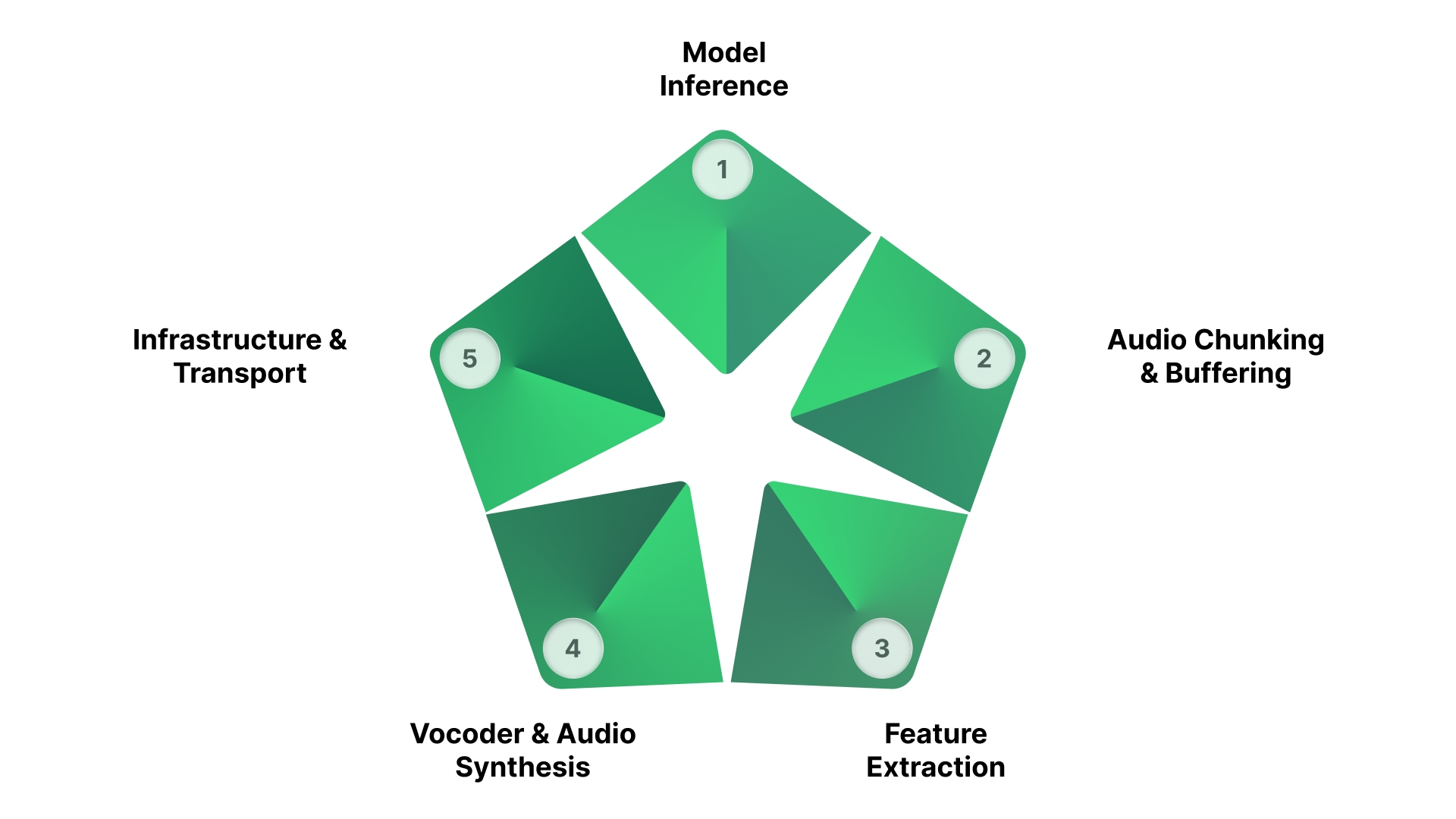
Even well-designed systems can struggle with latency because delays do not come from a single source. They build up across the entire pipeline.
/divi:paragraph divi:paragraphTo reduce latency effectively, it is important to understand where these delays originate:
/divi:paragraph divi:heading {"level":3}Model Inference
/divi:heading divi:paragraphAt the core of the system, neural models process incoming audio frames.
/divi:paragraph divi:list- divi:list-item
- Larger models take longer to process each frame divi:list-item
- Autoregressive architectures introduce sequential delays divi:list-item
- High-quality models often trade speed for realism
Audio Chunking and Buffering
/divi:heading divi:paragraphHow audio is segmented has a direct impact on responsiveness.
/divi:paragraph divi:list- divi:list-item
- Larger chunks reduce compute overhead but increase delay divi:list-item
- Smaller chunks improve responsiveness but increase processing load divi:list-item
- Excess buffering adds hidden latency that compounds over time
Feature Extraction
/divi:heading divi:paragraphBefore transformation happens, the system needs to understand the voice.
/divi:paragraph divi:list- divi:list-item
- Pitch and spectral analysis introduce additional processing time divi:list-item
- Complex representations slow down streaming pipelines divi:list-item
- Inefficient feature computation blocks real-time flow
Vocoder and Audio Synthesis
/divi:heading divi:paragraphGenerating the final audio is often the slowest step.
/divi:paragraph divi:list- divi:list-item
- High-fidelity vocoders can become bottlenecks divi:list-item
- Sequential synthesis increases latency significantly divi:list-item
- Parallel generation is essential for real-time output
Infrastructure and Transport
/divi:heading divi:paragraphEven if the model is fast, delivery can introduce delays.
/divi:paragraph divi:list- divi:list-item
- Network round trips add milliseconds quickly divi:list-item
- Cold starts delay model availability divi:list-item
- Poor streaming protocols disrupt continuous audio flow
Latency is rarely caused by one issue. It is the result of small delays across multiple stages adding up.
/divi:paragraph divi:image {"lightbox":{"enabled":false},"id":20208640,"sizeSlug":"full","linkDestination":"custom","align":"center"} /divi:image divi:headingWhat It Takes to Achieve Voice Conversion Low Latency
/divi:heading divi:paragraphReducing latency in real-time voice conversion requires intentional design choices across models, data flow, and execution. The most effective systems combine multiple techniques rather than relying on a single optimization.
/divi:paragraph divi:heading {"level":3}Streaming-First Model Design
/divi:heading divi:list- divi:list-item
- Use causal or streaming-compatible architectures that do not rely on future audio context divi:list-item
- Eliminate lookahead windows that introduce an unavoidable delay divi:list-item
- Process audio incrementally rather than waiting for full segments
Lightweight Acoustic Representations
/divi:heading divi:list- divi:list-item
- Replace heavy spectral features with compact content embeddings divi:list-item
- Minimize preprocessing steps that block the streaming pipeline divi:list-item
- Prioritize representations that can be computed per frame
Fast, Parallel Vocoders
/divi:heading divi:list- divi:list-item
- Favor non-autoregressive vocoders for waveform generation divi:list-item
- Generate audio samples in parallel rather than sequentially divi:list-item
- Balance synthesis quality against real-time performance constraints
Model Optimization Techniques
/divi:heading divi:list- divi:list-item
- Apply quantization to reduce inference time divi:list-item
- Use pruning to remove redundant parameters divi:list-item
- Distill larger models into smaller, faster variants for production
Pipeline-Level Parallelism
/divi:heading divi:list- divi:list-item
- Overlap feature extraction, conversion, and synthesis where possible divi:list-item
- Avoid synchronous blocking between pipeline stages divi:list-item
- Keep buffers shallow to prevent latency buildup
Low-latency voice conversion is achieved by stacking these techniques together. Each one may save only a few milliseconds, but combined, they determine whether a system can operate comfortably in real time.
/divi:paragraph divi:paragraphAlso Read: Detecting Altered Voice with AI Deepfake Tools
/divi:paragraph divi:headingWhy Infrastructure Has a Bigger Role Than Most Teams Think
/divi:heading divi:paragraphEven after optimizing models and pipelines, infrastructure determines whether real-time performance holds up in production.
/divi:paragraph divi:image
Edge and Region-Aware Deployment
/divi:heading divi:paragraphReducing physical distance between user and system minimizes delay.
/divi:paragraph divi:list- divi:list-item
- Run inference closer to users to reduce network latency divi:list-item
- Choose cloud regions based on user geography divi:list-item
- Use edge nodes when full on-device processing is not possible
Persistent Model Execution
/divi:heading divi:paragraphCold starts can break real-time systems.
/divi:paragraph divi:list- divi:list-item
- Keep models warm to avoid initialization delays divi:list-item
- Avoid repeated loading of large model weights divi:list-item
- Use long-lived inference workers
Real-Time Audio Transport
/divi:heading divi:paragraphTransport design directly impacts latency.
/divi:paragraph divi:list- divi:list-item
- Use streaming protocols built for real-time audio divi:list-item
- Avoid request-response patterns for live voice divi:list-item
- Maintain continuous audio flow instead of bursts
Resource Allocation and Scheduling
/divi:heading divi:paragraphConsistency matters as much as speed.
/divi:paragraph divi:list- divi:list-item
- Reserve compute resources for real-time workloads divi:list-item
- Prevent contention with batch processing jobs divi:list-item
- Monitor tail latency, not just averages
Fault Tolerance Without Delay Spikes
/divi:heading divi:paragraphFailures should not interrupt the experience.
/divi:paragraph divi:list- divi:list-item
- Handle packet loss without restarting streams divi:list-item
- Design graceful degradation instead of hard resets divi:list-item
- Keep recovery lightweight to avoid latency spikes
In production systems, predictability matters as much as raw speed. A system that performs well only under ideal conditions is not truly real-time.
/divi:paragraph divi:paragraphAlso Read: 10 Best AI Tools for Text-to-Speech Conversion
/divi:paragraph divi:headingThe Use Cases That Fall Apart When Latency Creeps In
/divi:heading divi:paragraphNot all applications are equally sensitive to delay. However, some use cases break immediately when latency increases.
/divi:paragraph divi:heading {"level":3}Live Customer Support
/divi:heading divi:paragraphReal-time voice transformation must keep up with conversation flow.
/divi:paragraph divi:list- divi:list-item
- Delays disrupt turn-taking between agent and customer divi:list-item
- Responses feel unnatural when timing is off divi:list-item
- Latency spikes are instantly noticeable
Gaming and Virtual Worlds
/divi:heading divi:paragraphImmersion depends heavily on timing.
/divi:paragraph divi:list- divi:list-item
- Player voices are transformed into character voices divi:list-item
- Even slight delays affect coordination and realism divi:list-item
- Lag reduces engagement and fairness
Real-Time Dubbing and Localization
/divi:heading divi:paragraphAudio must stay synchronized with visuals.
/divi:paragraph divi:list- divi:list-item
- Voice output must align with lip movements divi:list-item
- Delays create noticeable mismatch divi:list-item
- Drift quickly breaks immersion
Accessibility and Assistive Communication
/divi:heading divi:paragraphClarity and pacing are critical.
/divi:paragraph divi:list- divi:list-item
- Voice conversion supports users with speech impairments divi:list-item
- Delays increase cognitive load for listeners divi:list-item
- Natural timing improves comprehension
Secure Communication Systems
/divi:heading divi:paragraphReal-time processing must remain seamless and reliable.
/divi:paragraph divi:list- divi:list-item
- Voice anonymization must happen instantly divi:list-item
- Delays expose processing boundaries divi:list-item
- Systems must avoid artifacts during transformation
As voice systems scale, the stakes go beyond experience. Faster systems must also address misuse risks such as impersonation and fraud.
/divi:paragraph divi:paragraphThe stakes are rising beyond user experience. According to the U.S. Federal Trade Commission, consumers reported $2.7 billion in losses from imposter scams in 2024, with voice impersonation playing a growing role. As real-time voice systems become more powerful, latency is not the only requirement. Systems must respond instantly while maintaining safeguards against misuse.
/divi:paragraph divi:headingThe Safety Problem Real-Time Voice Conversion Cannot Ignore
/divi:heading divi:paragraphLow-latency voice conversion introduces challenges that go beyond performance. When systems operate in real time, there is little opportunity to pause, review, or intervene, which raises important ethical and security concerns.
/divi:paragraph divi:image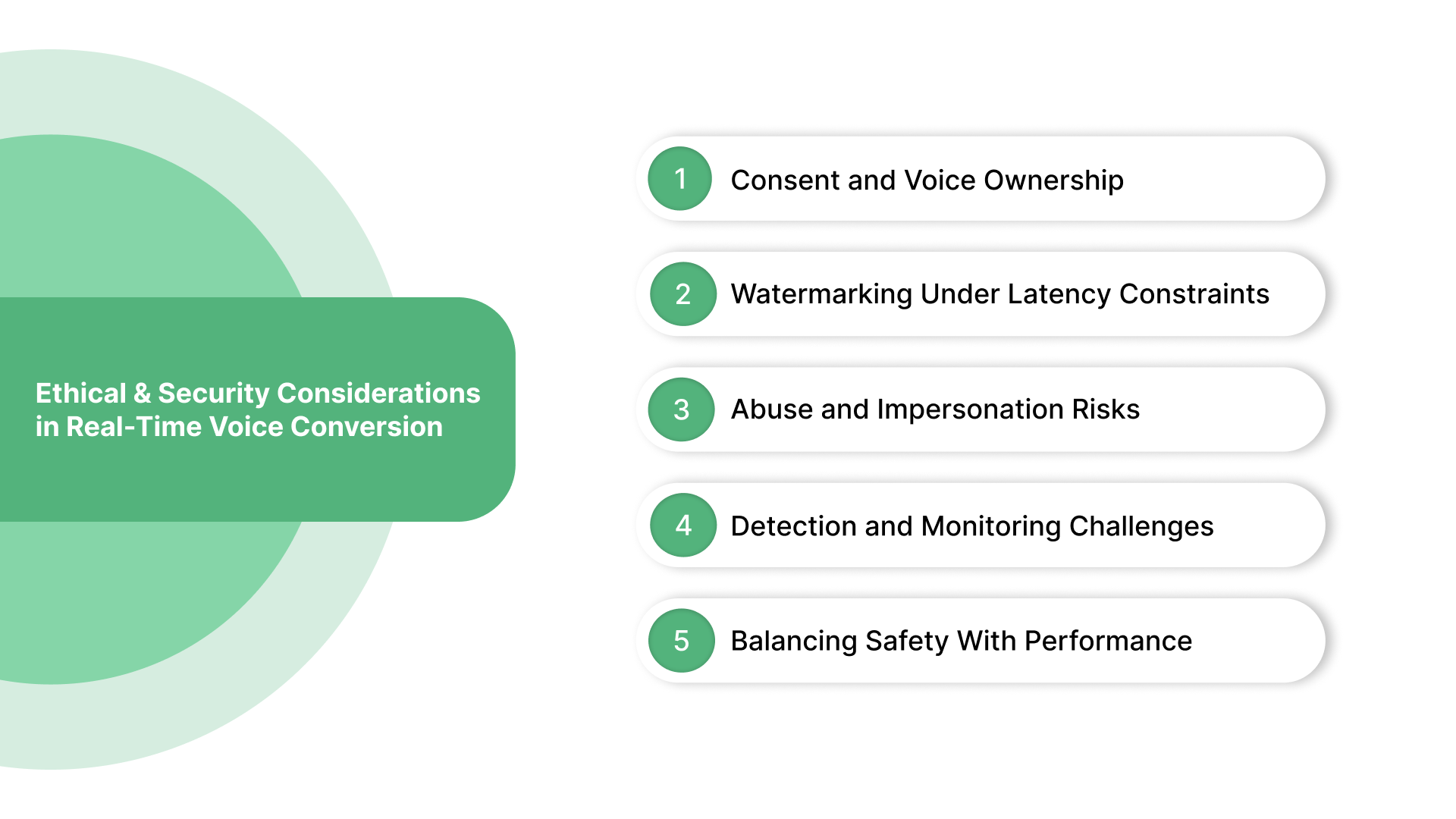
Consent and Voice Ownership
/divi:heading divi:list- divi:list-item
- Real-time systems must verify that voices are used with explicit permission divi:list-item
- Live conversion removes the buffer where consent checks are often enforced divi:list-item
- Voice misuse becomes harder to detect once audio is streamed instantly
Watermarking Under Latency Constraints
/divi:heading divi:list- divi:list-item
- Audio watermarking must run without adding perceptible delay divi:list-item
- Lightweight, streaming-safe watermarking is required for real-time pipelines divi:list-item
- Post-processing watermarking is not viable for live systems
Abuse and Impersonation Risks
/divi:heading divi:list- divi:list-item
- Real-time conversion can be misused for live impersonation divi:list-item
- Faster systems reduce detection windows divi:list-item
- Safeguards must operate in line rather than after the fact
Detection and Monitoring Challenges
/divi:heading divi:list- divi:list-item
- Traditional deepfake detection assumes offline analysis divi:list-item
- Real-time conversion limits inspection depth divi:list-item
- Systems must rely on continuous signals instead of full-audio review
Balancing Safety With Performance
/divi:heading divi:list- divi:list-item
- Security checks add computational overhead divi:list-item
- Overly aggressive safeguards can break real-time constraints divi:list-item
- Ethical design requires safety mechanisms that scale with speed
In real-time voice conversion, ethical safeguards must be built into the core pipeline. Treating them as add-ons introduces risk, both technically and socially.
/divi:paragraph divi:headingHow Resemble AI Brings Low-Latency Voice Conversion to Production
/divi:heading divi:paragraphThis is where Resemble AI differentiates itself. Its platform is designed around streaming-first speech-to-speech pipelines, allowing audio to be transformed continuously without waiting for full utterances. This ensures consistent performance in live, bidirectional environments where even small delays can break interaction flow.
/divi:paragraph divi:paragraphBeyond performance, Resemble AI integrates real-time safety mechanisms directly into the generation pipeline, rather than treating them as post-processing layers.
/divi:paragraph divi:heading {"level":3}Key Capabilities That Support Voice Conversion Low Latency
/divi:heading divi:paragraphTo achieve both speed and reliability, the platform combines multiple layers of optimization and control:
/divi:paragraph divi:list- divi:list-item
- Low-latency streaming APIs: Designed for continuous audio input and output, eliminating batch processing delays and enabling real-time speech-to-speech conversion divi:list-item
- Custom voice models optimized for real-time inference: Models are tuned for stability and speed, ensuring consistent voice output without introducing processing lag divi:list-item
- Parallelized speech synthesis pipeline: Audio generation is handled in a way that avoids sequential bottlenecks, keeping output aligned with live input divi:list-item
- Scalable, session-aware infrastructure: Supports long-running, real-time sessions without cold starts or performance degradation
Real-Time AI Watermarking Without Latency Trade-Offs
/divi:heading divi:paragraphOne of the most critical challenges in real-time voice systems is adding traceability without slowing down the pipeline. Traditional watermarking approaches often rely on post-processing, which is not viable in live environments.
/divi:paragraph divi:paragraphResemble AI addresses this with its AI Watermarker, designed specifically for real-time and production use cases:
/divi:paragraph divi:list- divi:list-item
- Embedded during audio generation, not after: Watermarks are applied inline within the synthesis process, eliminating the need for additional processing stages divi:list-item
- Perceptually invisible yet machine-detectable: The watermark does not affect audio quality or user experience, but can still be reliably identified by detection systems divi:list-item
- Persistent across transformations: The watermark remains intact even after compression, streaming, or format changes, ensuring traceability across platforms divi:list-item
- Low-overhead design for streaming systems: Built to operate within tight latency budgets, ensuring watermarking does not introduce noticeable delay divi:list-item
- Supports IP protection and misuse detection: Enables organizations to verify whether audio was generated or modified using their systems, helping address impersonation and misinformation risks
This approach is critical for voice conversion low latency systems, where there is no opportunity to pause and apply safeguards after the fact. By embedding watermarking directly into the generation layer, Resemble AI ensures that security scales with speed.
/divi:paragraph divi:heading {"level":3}Integrated Detection and Safeguards
/divi:heading divi:paragraphIn addition to watermarking, Resemble AI strengthens real-time systems with built-in detection and control mechanisms:
/divi:paragraph divi:list- divi:list-item
- DETECT-3B deepfake detection: Identifies synthetic or altered audio across multiple languages and voice types divi:list-item
- Inline consent and usage controls: Ensures voices are used within authorized boundaries during live sessions divi:list-item
- Real-time monitoring signals: Supports continuous verification without requiring full audio analysis
Because these capabilities are built into the same pipeline as voice generation, they operate without introducing latency spikes or breaking streaming flow.
/divi:paragraph divi:paragraphFor teams moving from experimentation to production, this combination of low-latency performance and inline safeguards removes a major barrier. It allows voice conversion systems to scale while maintaining control, traceability, and reliability.
/divi:paragraph divi:image {"lightbox":{"enabled":false},"id":20208641,"sizeSlug":"large","linkDestination":"custom","align":"center"} /divi:image divi:headingConclusion
/divi:heading divi:paragraphReal-time voice conversion only works when latency stays out of the conversation. Systems that respond instantly feel natural, trustworthy, and ready for production. Those that do not quickly fall apart in live use.
/divi:paragraph divi:paragraphBuilding for low latency from the start is what turns voice conversion into a reliable, real-time capability instead of a fragile demo. It enables use cases that depend on timing, consistency, and scale.
/divi:paragraph divi:paragraphResemble AI provides real-time, low-latency voice conversion built for production environments, with streaming APIs, custom voices, and responsible AI safeguards. With real-time streaming, built-in AI Watermarking, and DETECT-3B verification, modern voice systems can deliver both speed and trust.
/divi:paragraph divi:paragraphIf you are building live voice experiences, request a demo of Resemble AI to see how real-time voice conversion performs when latency actually matters.
/divi:paragraph divi:headingFAQs
/divi:heading divi:heading {"level":3}Q: What is low latency in audio?
/divi:heading divi:paragraphA: Low latency in audio refers to the minimal delay between when a sound is produced and when it is heard. In real-time voice systems, low latency is essential to maintain natural conversation flow and prevent noticeable delays.
/divi:paragraph divi:heading {"level":3}Q: What is voice latency?
/divi:heading divi:paragraphA: Voice latency is the time it takes for spoken audio to be captured, processed, transmitted, and played back to a listener. High voice latency can cause interruptions, overlaps, and reduced trust in real-time voice applications.
/divi:paragraph divi:heading {"level":3}Q: What is the lowest latency TTS?
/divi:heading divi:paragraphA: The lowest latency text-to-speech systems use streaming and non-autoregressive models to generate audio in near real time. These systems prioritize fast audio synthesis so speech can begin playing almost immediately after text input.
/divi:paragraph divi:heading {"level":3}Q: What is acceptable latency for real-time voice conversion?
/divi:heading divi:paragraphA: Acceptable latency for real-time voice conversion is low enough that users do not perceive a delay during conversation. Systems designed for live interaction aim to stay within tight latency budgets across processing and transport.
/divi:paragraph divi:heading {"level":3}Q: How does low latency affect voice AI user experience?
/divi:heading divi:paragraphA: Low latency directly impacts how natural and responsive a voice system feels. Faster responses improve conversational flow, while delays quickly break immersion in live voice interactions.
/divi:paragraph.avif)

