Production-grade TTS with zero-shot voice cloning. Outperforms ElevenLabs in blind evaluations. First open-source model with emotion exaggeration control.
Can generic TTS handle your edge cases? Chatterbox does.
Drug name or brand terminology
PRONOUNCED CORRECTLY
PRONOUNCED CORRECTLY
Emotion and vocal character
CONSISTENT OUTPUT
CONSISTENT OUTPUT
Live agent response at 200ms TTFS
NO PERCEPTIBLE DELAY
NO PERCEPTIBLE DELAY
Deployed on your own infrastructure
FULL CONTROL
FULL CONTROL
Voice clone across 23 languages
ACCENT RETAINED
ACCENT RETAINED
Sighs, laughs, and gasps built in
NO POST-PROCESSING
NO POST-PROCESSING
OUR CAPABILITIES
Speech that responds instantly, pronounces correctly, and sounds human.
The details that break generic TTS are the ones we designed around.
Real time streaming
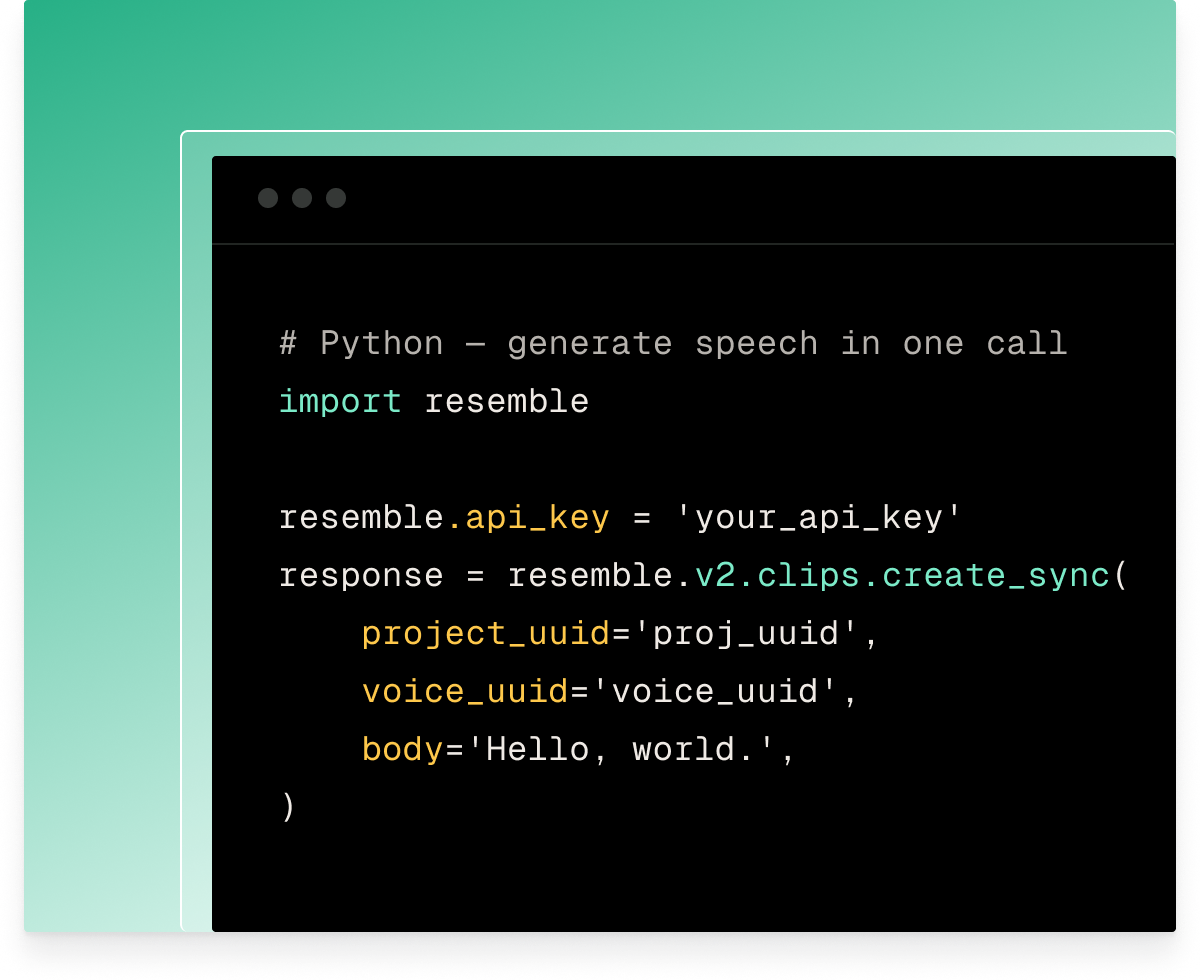
Delivers speech via WebSocket at 200ms TTFS for conversational agents, HTTP streaming for longer-form content, and synchronous responses for notifications. One API, with three modes matched to how your application works.
Custom pronounciation
Generates multiple pronunciation variants for any term and lock in the best one. The approved pronunciation applies across every voice, session, and API call automatically.
Emotion and paralinguistic control
Adjusts emotion intensity from flat delivery to dramatically expressive with a single parameter. Chatterbox Turbo adds natural vocal reactions inline — sighs, laughs, coughs, gasps without post-processing.
200ms
Time to first speech with Chatterbox Turbo
10M+
Hugging Face downloads, including 2.2M in a single month
100
Languages and regional dialects supported on the managed platform
Resemble tts use cases
Built for industries where the voice has to be right.
Standard TTS handles the easy cases. These don't have room for error.
Voice Agents & IVR
The problem:
Generic TTS introduces perceptible delay and flat delivery that breaks conversational trust.
Resemble AI solution:
200ms TTFS via WebSocket. Natural vocal reactions built in. Agents sound human.
Contact Centers
Industry risk:
Multiple TTS vendors per language, each with different latency and quality profiles.
Resemble AI solution:
One API. 100 languages. Single integration point for the entire contact center stack.
Developer Platforms
The problem:
Vendor lock-in and data sovereignty concerns block enterprise AI voice deployments.
Resemble AI solution:
MIT-licensed. Deploy cloud, on-premise, or air-gapped. No vendor lock-in.
Media & Localization
The problem:
Voice clones lose accent and character when translated across languages.
Resemble AI solution:
Zero-shot cloning retains vocal identity across 23 languages from 5 seconds of audio.
Healthcare & HealthTech
The problem:
Drug names, fund tickers, and legal citations mispronounce on every generic engine.
Resemble AI solution:
Lock the correct pronunciation once. It applies across every voice and API call.
Regulated Industries
The problem:
AI-generated audio output not traceable for compliance or governance review.
Resemble AI solution:
Every file can add a PerTh neural watermark. Provenance is verifiable at any point.
Does TTS affect audio quality at production grade?
No. Quality metrics remain consistent across cloud API, on-premise, and open-source deployments.
What languages are supported?
100 languages and regional dialects on the managed platform. 23 languages with full zero-shot voice cloning via Chatterbox Multilingual: English, Spanish, French, German, Arabic, Portuguese, Russian, Turkish, Italian, Danish, Finnish, Japanese, Korean, Mandarin, Dutch, Slovak, Swedish, Vietnamese, Norwegian, Polish, Swahili, Hindi, and Hebrew.
How does custom pronunciation work?
Submit a term through the vocabulary engine and it returns multiple pronunciation variants. Select the correct one in one click. The locked pronunciation applies across all voices, sessions, and API calls. No phonetic transcription required.
Can I clone a voice without training data?
Yes. 5 seconds of reference audio, no training. Accent and vocal character retained across all 23 languages.
IIs the model truly open-source?
Yes. Chatterbox is MIT-licensed on GitHub and Hugging Face. Run it on your own infrastructure, audit the weights, keep your data sovereign.
What are the enterprise deployment options and SLAs?
Cloud API, on-premise, and air-gapped environments. Chatterbox Multilingual Pro includes sub-200ms latency SLAs, guaranteed uptime, and custom fine-tuning on brand vocabulary. SLA documentation available on request.
How quickly can we integrate?
Most teams are live within a day using the REST API or an available SDK. Open-source deployment via Hugging Face requires no API key.
Get complete generative AI security
Join thousands of developers and enterprises securing with Resemble AI