

Tools For Verifying Safe Generative Voice AI. As artificial intelligence (AI) generated voices become increasingly close to human-level quality, Resemble AI is providing additional tools to help the industry tackle malicious use and stop misinformation. To deploy safe neural speech in the wild, Resemble AI is introducing the PerTh Watermarker, a deep neural network watermarker. The data is embedded in an imperceptible and difficult-to-detect way, acting as an “invisible watermark” that is both difficult to remove, and provides a way to verify if a given clip was generated by Resemble.
The Importance of Detection
Advanced photo editing software has made it impossible to rely on images alone to determine the legitimacy of information. Nowadays, there are many tools available to edit images, video, and audio, but one must be skilled in using these tools to create a convincing result. Despite this, there are plenty of people capable of using these tools, so we must be aware that content from unknown sources could be manipulated. Nevertheless, even with access to advanced tools and knowledge, it is still difficult to generate completely new content, rather than just modifying existing material.
These barriers of skill and content generation are rapidly being dismantled by the new wave of AI generative models that have surfaced in recent months. Many researchers and companies already claim to generate image, speech, and video content that is indistinguishable from real content. Typically, some technical expertise is required to use these tools. However, many companies, including ours, strive to make them as easy to use as possible, reducing or eliminating the need for any specific technical knowledge. Without proper verification in place, this could lead to the proliferation of fake and misleading content, which can even make its way into the pages of well-intentioned and reputable news organizations.
One way to tackle this emerging issue is to instead use AI as a tool to detect whether content is genuine. After all, if the AI is powerful enough to fool our senses with generated content, then perhaps it’s also more powerful than our ability to detect fake content. The challenging field of fake content detection is a very active area of research, including here at Resemble. However, we still have more work to do, as the cat-and-mouse game between generation and detection continues.
Despite the challenges posed by unverified users and data, practitioners can still take action. For instance, at Resemble, we require users to provide a recording of a consent clip in the voice they are attempting to clone. If the voice in this clip does not match the other clips, the user is blocked from creating the AI voice. If they manage to use deep-faking to manipulate the consent clip, they must already have access to deep-faking tools.
In our opinion, this was a start but no longer is enough to combat the problem. Therefore, we have developed an additional layer of security that uses machine learning models to both embed packets of data into the speech content that we generate, and recover said data at a later point. The data is embedded in an imperceptible and difficult-to-detect way, acting as an “invisible watermark.” Because the data is imperceptible, while being tightly coupled to the speech information, it is both difficult to remove, and provides a way to verify if a given clip was generated by Resemble. Importantly, this “watermarking” technique is also tolerant of various audio manipulations like speeding up, slowing down, converting to compressed formats like MP3, etc.
What Is A Watermarker? A watermarker is a tool that adds a digital watermark to an audio clip. This watermark can be used to identify the source of the clip or to prove that the clip has not been tampered with. The PerTh Watermarker from Resemble AI is a deep neural network watermarker that embeds data in an imperceptible and difficult-to-detect way.
How Does The PerTh Watermarker Work? Our model is called PerTh, which is a combination of Perceptual and Threshold. It was designed around the concept of exploiting the way we perceive audio to find sounds that are inaudible, and then encoding data into these regions. Further care is taken to ensure we can extract the embedded data from any part of the audio (aside from silence), and that the data is encoded into frequencies most common for speech. This ensures our data payload is difficult to corrupt with common audio manipulations.
We use Psychoacoustics (the study of human sound perception) to find the best way to encode the data. One psychoacoustic phenomenon is that we have varying sensitivity to different frequencies — this means we can embed more information into frequencies we are less sensitive to. Another, more interesting effect called “auditory masking” also exists, in which quiet sounds nearby in frequency and time to a louder sound are not perceived. As a result, the masking sound (the louder sound) produces a “blanket” in amplitude-frequency-time space that drowns out other sounds beneath it. Below is an example in the frequency-amplitude space:
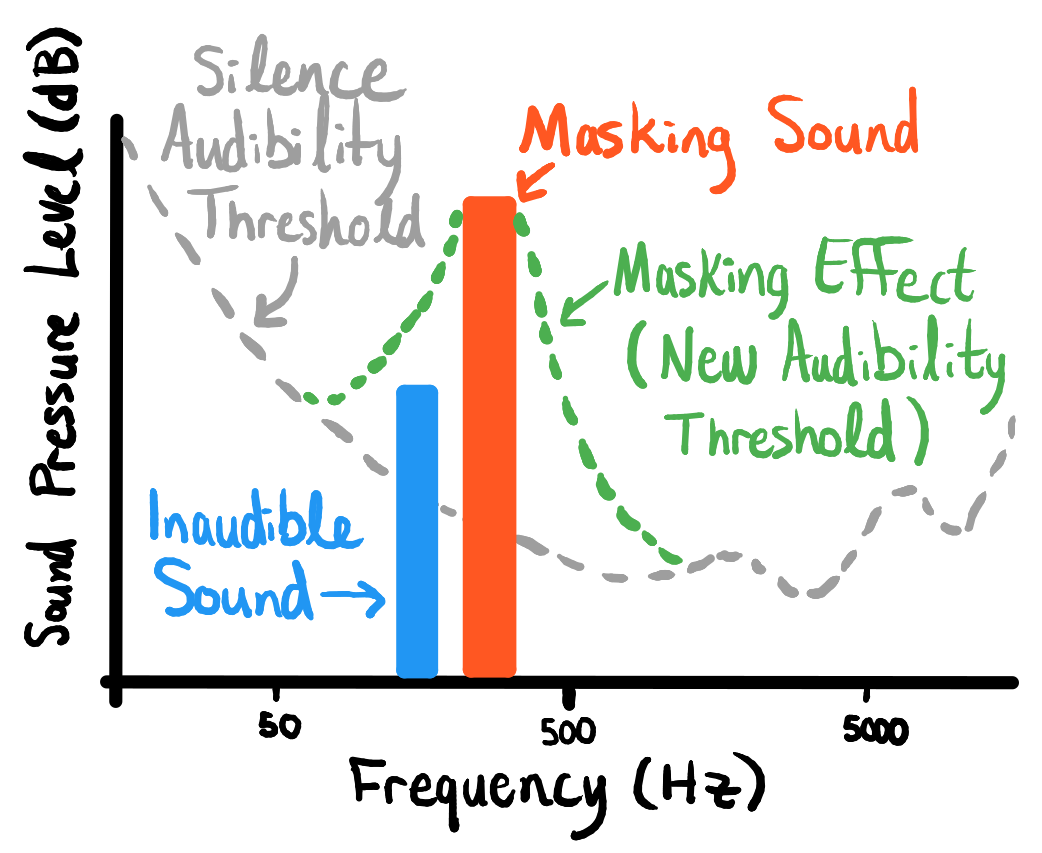
This effect is complicated and is dependant on the frequency of the masker sound, as depicted by the following figure:

Here are two synthetic audio files from the same speaker generated by the Resemble engine. One file has the watermark applied, while the other does not.
Without Watermark
With Watermark
In addition to exploiting psychoacoustics, we apply various regularization methods to the model training procedure to resist certain types of attacks. For example, adding audible noise, applying time-stretching, time-shifting, and so on to the watermarked audio before decoding the embedded data. Using these ideas we can obtain nearly 100% data recovery rate even after applying various “attacks” such as resampling, re-encoding, etc. The following figure shows the results of a typical attack suite against this method:
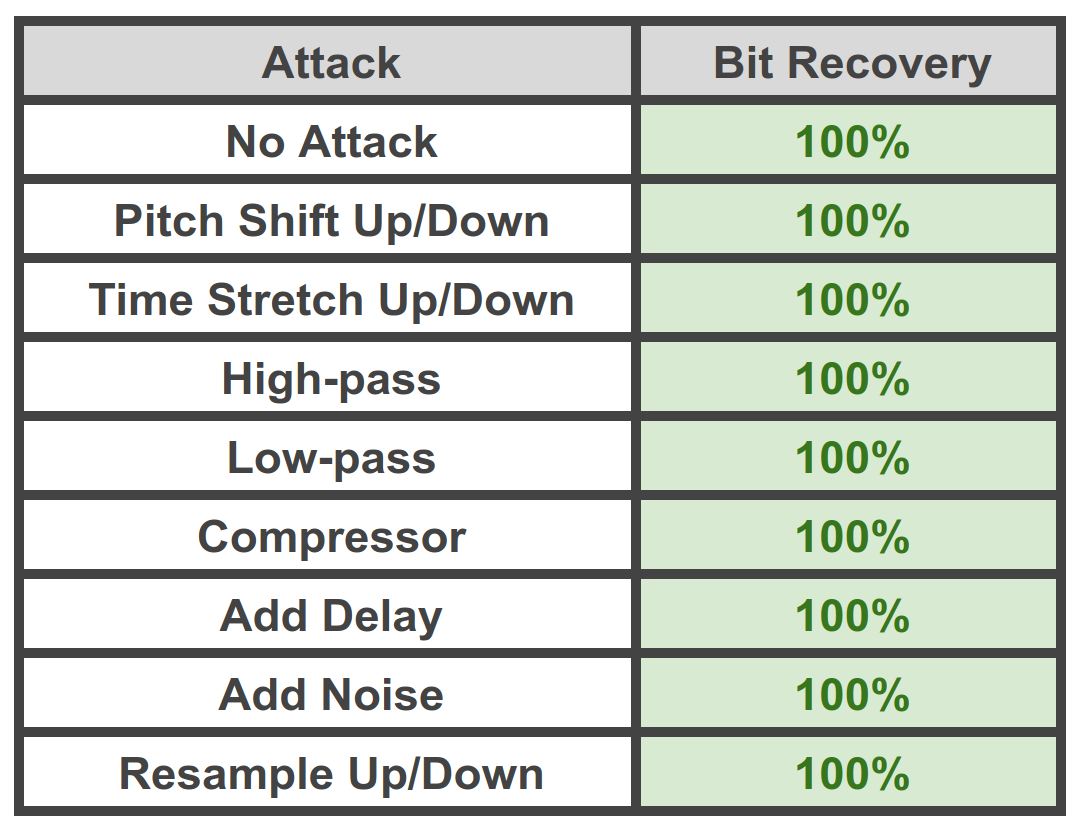
Benefits of the PerTh Watermarker. The PerTh Watermarker provides a reliable and secure way to deploy neural speech in the wild. It allows users to identify the source of an audio clip and to verify if a clip has been tampered with. The watermark is tightly coupled to the speech information, making it both difficult to remove and a reliable way to detect Resemble generated audio.
What it Means for Resemble’s Customers. The PerTh Watermarker will soon rollout to all customers. It has no effect on how thousands of Resemble customers are using AI voices in their respective applications, but it will be an added layer of protection that ensures only Resemble generated audio is used, and that any manipulation of the audio will be easily detectable. The watermark is also completely transparent to the user, as it is embedded in an imperceptible and difficult-to-detect way. This means that the audio generated by Resemble will remain of the highest quality.
Just as Photoshop and After Effects changed our relationship with digital content, generative AI is charging quickly ahead to the same effect. Our goal is to ensure care is taken that the field is not blindly charging ahead. Thinking harder about tracking and detection in the tools we provide may not just be an integral part of that effort, but perhaps a legally required one in a not-too-distant future.


