What is the difference between Audio Edit and Audio Enhancement?
Audio Edit changes what was said in a recording using AI inpainting. It requires a Resemble voice. Audio Enhancement processes any audio file to improve quality. No voice required.
Does Audio Edit re-record the entire file?
No. Only the changed segment is regenerated. Everything else stays intact.
What audio formats does Audio Enhancement support?
WAV, MP3, M4A, MP4, OGG, AAC, and FLAC. Maximum file size 150 MB.
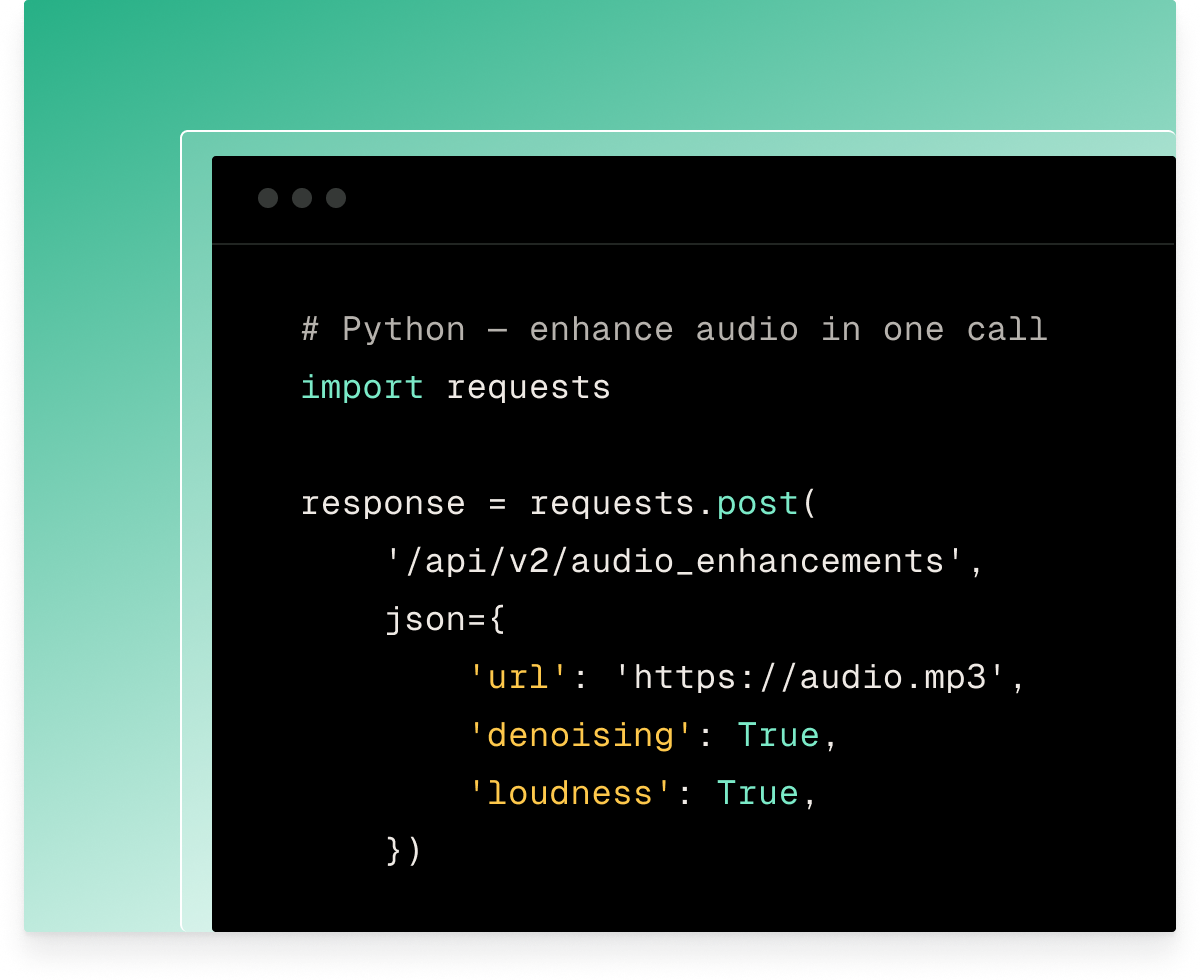
Can I control which processing parameters apply?
Yes. Noise removal, loudness normalization, and studio processing are all on by default. Each can be turned off independently per API call.
How are jobs processed and billed?
Both tools are asynchronous. Submit, poll for status, download on completion. Billed per second of processed audio. Failed jobs not billed.
Does Audio Edit work with any voice tool?
Audio Edit requires a Resemble voice UUID. Audio Enhancement works on any audio file regardless of origin.
Get complete generative AI security
Join thousands of developers and enterprises securing with Resemble AI